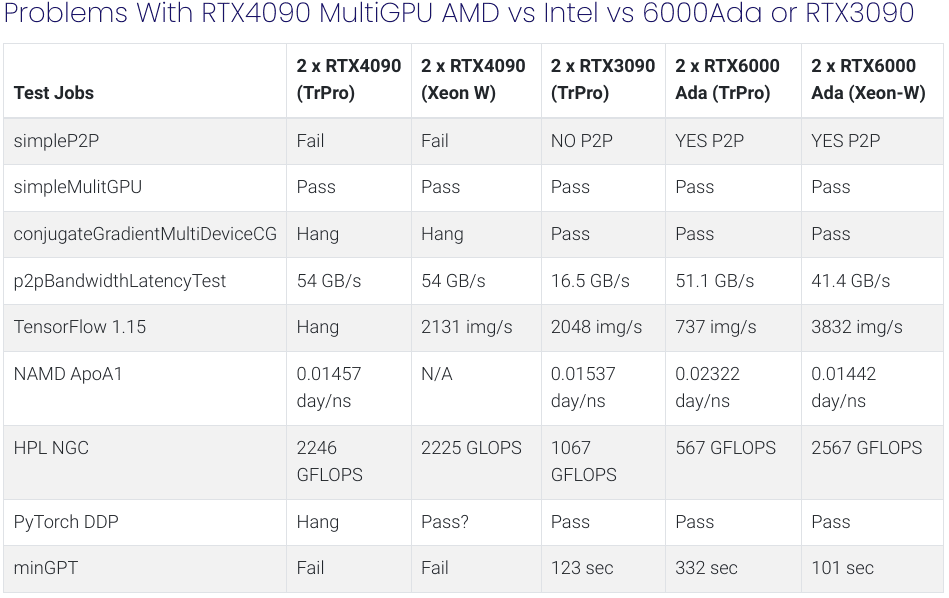
I was prompted to do some testing by a commenter on one of my recent posts. They had concerns about problems with dual NVIDIA RTX4090s on AMD Threadripper Pro platforms. I ran some applications to reproduce the problems reported above and tried to dig deeper into the issues with more extensive testing. The included table below tells all!