
Puget Systems at BCON LA 2024
Come visit Puget Systems at BCON LA and find out how our custom workstations, laptops, and storage systems can power your Blender workflows!
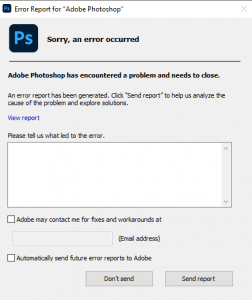
Photoshop Initial Troubleshooting Guide
Introduction Adobe Photoshop is a ubiquitous tool in the digital world known for its boundless capabilities in transforming, enhancing and creating stunning graphics. Yet, just like any software, it can sometimes throw up baffling errors and glitches that can disrupt the workflow or worse, lead to loss of hours put into a creation. This guide
Basic Guide to Improving Windows 11 Performance
Keeping a well-optimized computer system is crucial which is one reason you purchased from Puget Systems. When it comes to Windows 11, one of the latest offerings in the operating system category, there are several ways to ensure optimal performance.
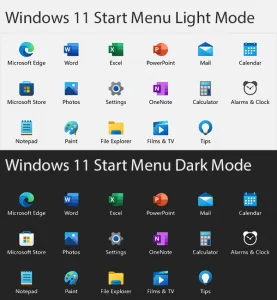
Feel the Pull of the Dark Side
Welcome to an enlightening journey into the exploration of Windows 11’s user interface with a particular focus on its highly sought-after feature – the dark mode.

Intel Core i9-14900KS Content Creation Review
The Intel i9-14900KS is a small top-end refresh on the 14900K targeted at enthusiasts. How much performance does the higher base TDP and boost clock gain?

Some Useful Windows 11 Shortcuts
Keyboard shortcuts act like secret keys to unlock swift functionality and save time. It’s akin to having a toolbox of power-tools at your fingertips. So let’s dive on into understanding the essential keyboard shortcuts in Windows 11 and explore their usefulness

AI-Driven Writing: Lessons from the Lab
With the explosion of ChatGPT and other AI tools, we wanted to see how they fit into the article writing we do here at Puget Systems.

Identifying Common PC Issues by Sound
Audio clips of various issues, warnings, and every day occurrences for your reference to help identify common issues.

Unreal Engine 5.4 Subscription: What You Need to Know
Today Epic unveiled pricing for their Unreal Subscription. We look into who needs to pay, and what features will be available at every level.

Puget Systems Laptop vs Desktop Performance Comparison for Content Creation
With the launch of the new Puget Systems 17″ laptop, there are a lot of performance questions we want to address. Today, we will be examining the performance of this new mobile workstation compared to a more traditional desktop.