Hardware Recommendations for Scientific Computing
Scientific computing is a vast domain with myriad individual applications that all have their own specific hardware needs, but the guidance here will get you started in the right direction for your next workstation.
Puget Labs Certified
These hardware configurations have been developed and verified through frequent testing by our Labs team. Click here for more details.
Scientific Computing System Requirements
Quickly Jump To: Processor (CPU) • Video Card (GPU) • Memory (RAM) • Storage (Drives)
Scientific Computing is a vast domain! There are thousands of “scientific” applications and it is often the case that what you are working with is based on your own code development efforts. Performance bottlenecks can arise from many types of hardware, software, and job-run characteristics. Recommendations on “system requirements” published by software vendors (or developers) may not be ideal. They could be based on outdated testing or limited configuration variation. However, it is possible to make some general recommendations. The Q&A discussion below, with answers provided by Dr. Donald Kinghorn, will hopefully prove useful. We also recommend that you visit his Puget Systems HPC blog for more info.
Processor (CPU)
The CPU may be the most important consideration for a scientific computing workstation. The best choice will depend on the parallel scalability of your application, memory access patterns, and whether GPU acceleration is available or not.
What CPU is best for scientific computing?
There are two main choices: Intel Xeon® (single or dual socket) and AMD Threadripper™ PRO / EPYC™ (which are based on the same technology). For the majority of cases our recommendation is single socket processors like Xeon 600 and Threadripper PRO. Current versions of these CPUs offer options with high core counts and large memory capacity without the need for the complexity, expense, and memory & core binding complications of dual socket systems.


System Image
Do more CPU cores make scientific computing faster?
This depends on two main factors:
- The parallel scalability of your application
- The memory-bound character of your application.
It is always good to understand how well your job runs will scale. To better understand that, check out the info about Amdhal’s Law in our HPC blog.
Also, if your application is memory-bound then it will be limited by memory channels and may give best performance with fewer cores. However, it is often an advantage to have many cores to provide more available higher level cache – even if you use less than half of the available cores on a regular basis. For a well scaling application, an Intel or AMD 32-core CPU will likely give good, balanced hardware utilization and performance.
What hardware components are most important for Scientific and Engineering Simulation applications?
Simulation workloads are the most common type of scientific computing. That includes molecular dynamics, computational chemistry, FEA, CFD, physics—pretty much all of scientific and engineering computing that isn’t searching, sorting, pattern matching, or counting something, like Genomics, for example. Many of these simulation workflows will have differing requirements. Some will be highly parallel, and some will be cache-limited or memory-bound. Hardware recommendations will also depend on problem size; you must have enough memory to run your job! The key factors that determine hardware recommendations for simulation workloads are:
- Parallel scalability – This needs to be determined on an individual application basis. Code authors/vendors or the user community will have information discussing this.
- Memory requirements – This, again, is dependent on the application, but a common rule of thumb is to have 4-8GB CPU memory per physical core. For example, a 64-core CPU would want 256 – 512GB of memory.
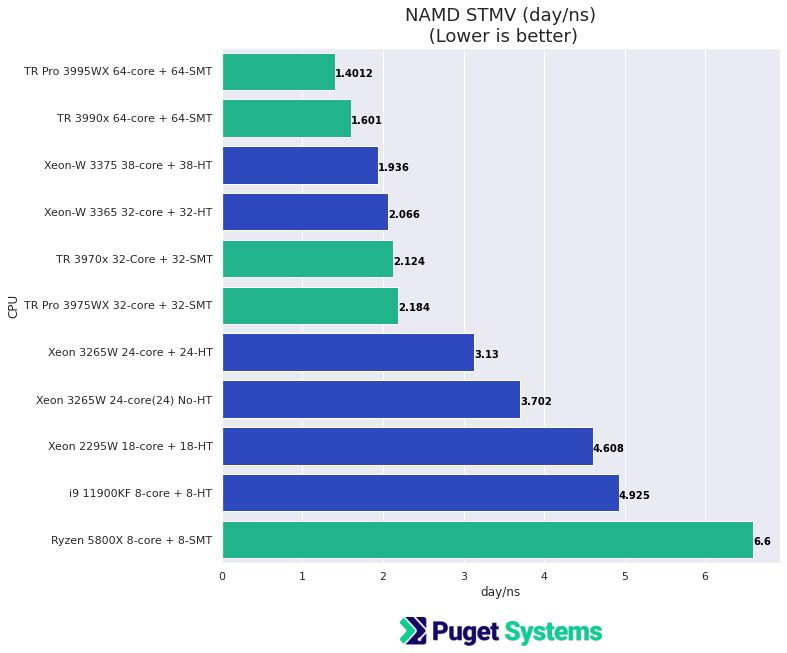
- Memory boundedness – The key differentiators are simulations involving numerical mesh-based “solvers” that may be memory-bound. This is a common issue, and failure to take it into account can result in a system configuration that may be over-spec for core count and amount of memory and bottlenecked by not having enough memory channels. Intel’s Xeon and AMD’s Threadripper PRO as well as EPYC are recommended. Dual EPYC CPUs will provide 24 total memory channels!
Example of a workload that is memory-bound
An increasing number of simulation codes are also running on GPU with great success, instead of the traditional CPU focus. When there is a GPU-accelerated version of an application, you should probably be using it! However, many important applications have not been ported to GPU because of programming difficulty/complexity. Time will tell, but mixed precision algorithms on GPU are very likely the future!
Does scientific computing work better with Intel or AMD CPUs?
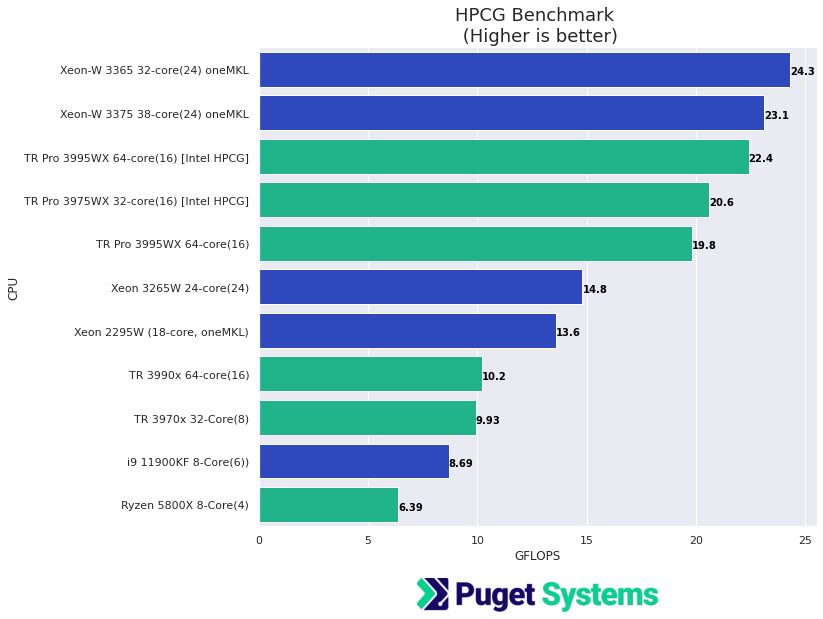
Either Intel Xeon or AMD Threadripper PRO processors are excellent. Both modern Xeon and Threadripper chips support AVX512, but older generations of AMD hardware were limited to AVX2. As long as you are buying a current-gen system, and not a consumer-grade platfrom, then they are equal there. However, newer Xeon processors do have a new edge: Advanced Matrix Extensions (AMX) and support for new data types like BF16. Those can have a big impact on mixed-precision workloads like AI computing. If your application is specifically linked with Intel MKL, or was built using an Intel compiler, then an Intel CPU is a good choice.
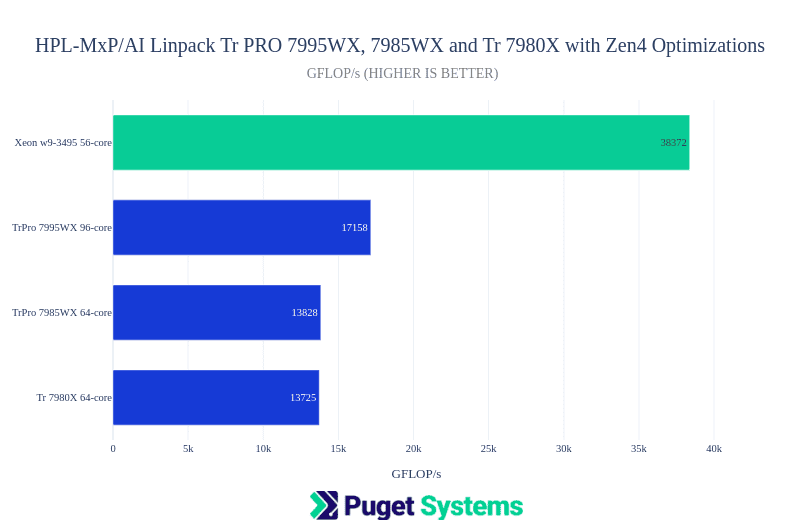
Example of a workload that benefits from Intel-specific processor capabilities
Why are Xeon or Threadripper PRO recommended rather than more “consumer” level CPUs?
The most important reason for this recommendation is memory channels. Most Intel Xeon 600 and AMD Threadripper PRO 9000 Series support 8 memory channels, which can have a significant impact on performance for many scientific applications. AMD’s EPYC 9005 series goes even further, with 12 memory channels per CPU! Another consideration is that all of these processors are “enterprise-grade” and the overall platform is likely to be robust under heavy sustained compute load compared to a consumer-grade system.
Looking for a Scientific Computing Workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with our technical consultants today.
Video Card (GPU)
If your application has GPU (graphics processing unit) acceleration then you should try to utilize it! Performance on GPUs can be many times greater than on CPUs for highly parallel calculations.
What GPU (video card) is best for scientific visualization?
If your use for the GPU is scientific visualization, then a good recommendation is a higher end NVIDIA RTX PRO™ card like the 4000 or 5000 Blackwell. If you are working with video data, very large images, or visual simulation then the 96GB of memory on the 6000 Blackwell may be an advantage. For a typical desktop display, lower-end NVIDIA professional series GPUs like the 2000 Blackwell may be plenty. NVIDIA’s “consumer” GeForce GPUs are also an option. Anything from the GeForce RTX™ 5060 Ti to RTX™ 5090 are very good. These GPUs are also excellent for more demanding 3D display requirements. However, it is a good idea to check with the vendor or developer of the software you are using to see if they have specific requirements for “professional” GPUs.


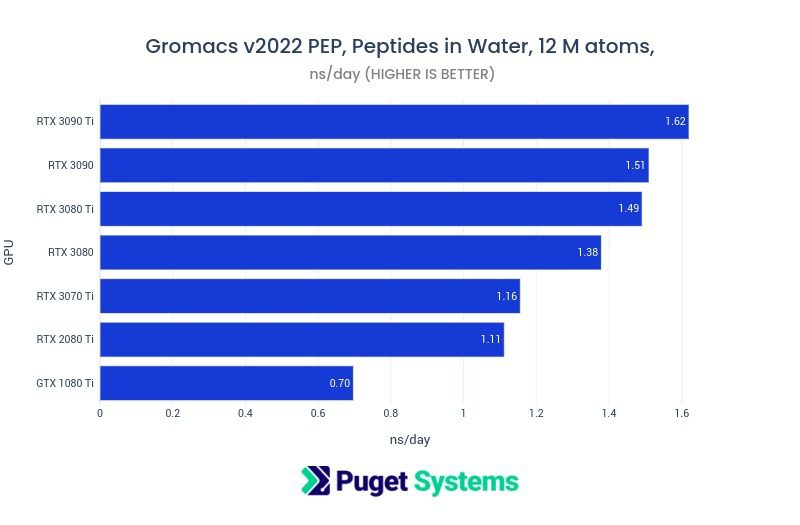
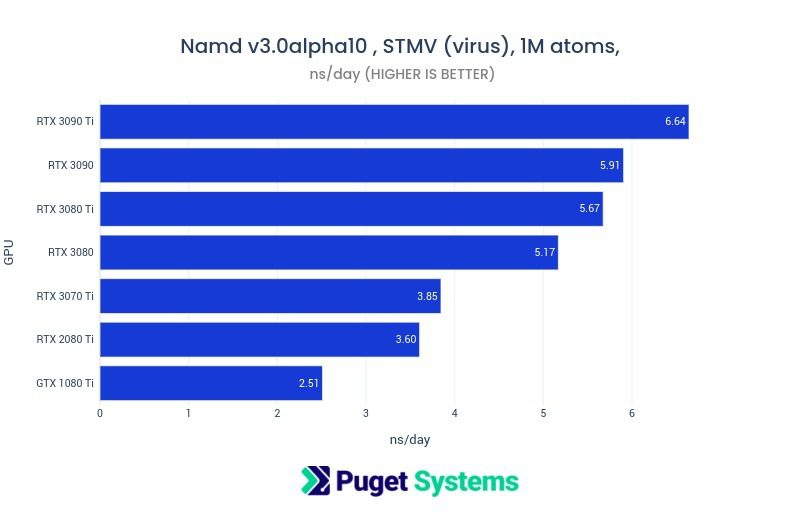
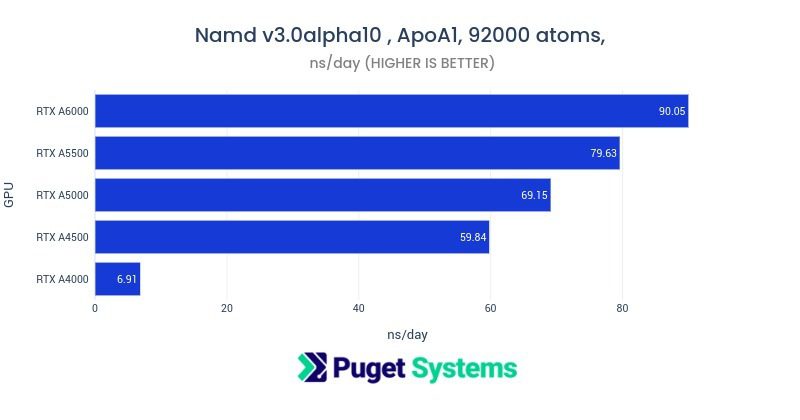
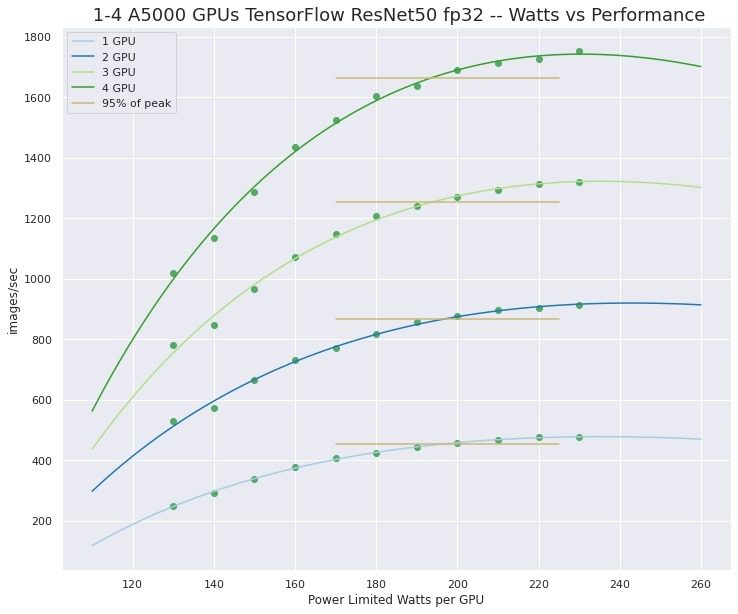
What video cards are recommended for GPU compute acceleration?
There are a few considerations. Do you need double precision (FP64) for your application? If so, then you are limited to the NVIDIA compute series – such as the L40S or H200. These GPUs are passively cooled and are suitable for use in rack mounted chassis with the needed cooling capability. None of the RTX GPUs, consumer or professional, have good double precision support.
Fortunately, many scientific applications that have GPU acceleration work with single precision (FP32). In this case the higher end RTX GPUs offer good performance and relatively low cost. GPUs like the RTX 6000 Ada and RTX PRO 6000 Blackwell Max-Q are high quality and work well in multi-GPU configurations. Consumer GPUs like GeForce RTX 5080 and 5090 can give very good performance but may be difficult to configure in a system with more than two GPUs because of cooling design and physical size.
In addition to the considerations already mentioned, memory size may be important is in general can be a limiting factor in the use of GPUs for compute.
How much VRAM (video memory) does scientific computing need?
This can vary depending on the application. Many applications will give good acceleration with as little as 12GB of GPU memory. However, if you are working with large jobs or big data sets then 32GB (4500 Blackwell, RTX 5090), 48GB (5000 Blackwell), or even 96GB (6000 Blackwell) may be required. For the most demanding jobs, NVIDIA’s H200 NVL compute GPU comes with a staggering 141GB of VRAM!
Will multiple GPUs improve performance in scientific computing?
Again this will depend on the application. Multi-GPU acceleration is not automatic just because you have more than one GPU in your system. The software has to support it. However, if your application scales well by distributing data or work across the GPUs, perhaps with Horovod (MPI), then a multi-GPU workstation can offer performance approaching that of a supercomputer of the not too distant past.
Does scientific computing need a “professional” video card?
Not necessarily – many important scientific calculations have been done on NVIDIA consumer GPUs. However, there are definitely things to consider – which we covered in more detail in the preceeding questions (above).
Does scientific computing run better on NVIDIA or AMD GPUs?
Thanks to their development of CUDA, and the numerous applications that use it, NVIDIA GPUs are currently the standard for scientific computing. While nearly all GPU-accelerated applications are built with CUDA, there is some usage of openCL (which is supported on AMD and NVIDIA GPUs) and there are utilities such as AMD’s own ROCm. However, those are not widely used and can be difficult to configure. This situation will certainly change as more work is done with the newly deployed AMD GPU-accelerated supercomputers and Intel’s entry into the GPU compute acceleration realm.
When is GPU acceleration not appropriate for scientific computing?
If you can use GPU acceleration then you probably should. However, if your application has memory demands exceeding that of GPUs or the high cost of NVIDIA compute GPUs is prohibitive then a many-core CPU may be appropriate instead. Of course if your application is not specifically written to support GPUs then there is no magic to make it work. Needing double precision accuracy for your calculations will also limit you either CPUs or NVIDIA compute-class GPUs, the latter of which are generally not suitable in a workstation and incur a high cost (but potentially offer stellar performance).
Looking for a Scientific Computing Workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with our technical consultants today.
Memory (RAM)
Memory performance and capacity are very important in many scientific applications. In fact, memory bandwidth will be the chief bottleneck in memory-bound programs. Applications that involve “solvers” for simulations may be doing solutions of differential equations that are often memory bound. This ties in with our recommendation of CPUs that provide 8 memory channels.
How much RAM does scientific computing need?
Since there are so many potential applications and job sizes this is highly dependent on the specific use case. It is fortunate that modern Intel and AMD workstation platforms support large memory configurations even in single-socket systems. For workflows focused on CPU-based calculations, 256 to 512GB is fairly typical – and even 1TB is not unheard of.
How much system memory do I need if I’m using GPU acceleration?
There general guidance on this. It is highly recommended that the system be configured with at least twice as much system memory (RAM) as there is total GPU memory (VRAM) across all cards. For example, a system with two GeForce RTX 5090 GPUs (2 x 32 = 64GB total VRAM) should have at least 128GB of system memory. This system memory recommendation is to ensure that memory can be mapped from GPU space to CPU space and to provide staging and buffering for instruction and data transfer without stalling.
Storage (Hard Drives)
Storage is one of those areas where going with “more than you think you need” is probably a good idea. The actual amount will depend on what sort of data you are working with. It could range from a few 10’s of gigabytes to several petabytes!
What storage configuration works best for scientific computing?
A good general recommendation is to use a highly performant NVMe drive of capacity 1TB as the main system drive – for the OS and applications. You may be able to configure additional NVMe storage for data needs, however there are larger capacities available with “standard” (SATA based) SSDs. For very large storage demands, older-style platter drives can offer even higher capacity. For exceptionally large demands, external storage servers may be the best option.
My application recommends configuring a “scratch space”, what should I use?
Scratch space has often been a configuration in quantum chemistry applications for storing integrals. There are other applications that also are built expecting an available scratch space. For these cases, an additional NVMe drive would be a very good option. However, if there is a configuration option in the software to avoid using out-of-core scratch then that may be the best option. The need for scratch space was common when system memory capacity was small. It is likely much better to increase your RAM size if it will let you avoid scratch space, as memory is orders of magnitude faster than even high-speed SSDs.
Should I use network attached storage for scientific computing?
Network-attached storage is another consideration. It’s become more common for workstation motherboards to have 10Gb Ethernet ports, allowing for network storage connections with reasonably good performance without the need for more specialized networking add-ons. Rackmount workstations and servers can have even faster network connections, often using more advanced cabling than simple RJ45, making options like software-defined storage appealing.
Looking for a Scientific Computing workstation?
We build computers that are tailor-made for your workflow.
Don’t know where to start? We can help!
Get in touch with one of our technical consultants today.