Table of Contents
Introduction
In some of our recent LLM testing for GPU performance, a question that has come up is what size of LLM should be used. In previous articles where we have tested LLM performance across NVIDIA Consumer and Professional cards, we chose to use a relatively small model, Phi-3-Mini-4K-Instruct. This model is comprised of a mere 3.8 billion parameters, which puts it at about half the size of the smallest Llama models at around 7 or 8 billion.
There are some distinct benefits to testing with a model of this modest size: primarily speed and compatibility. Because smaller models have smaller memory footprints, choosing a model like Phi-3 Mini allows us to test on almost any modern GPU, allowing us to compare performance across a wide range of cards. The quantized version of Phi-3 Mini we use in our testing is compact enough that even 4GB VRAM GPUs can load it and perform inference!
In addition, a model with a small number of parameters also allows testing to be completed relatively quickly. Within a group like the Labs team at Puget Systems, responsible for repeated testing of a wide variety of hardware, the duration of a given benchmark is an important consideration. The faster that a benchmark can be run while maintaining accuracy, the more testing we can do (either with a greater variety of cards or more loops for accuracy), so smaller models are appealing for that reason.
Author’s note: A simple analogy I use for LLM performance and parameter count is to compare the LLM to a DIY layered water filter. The more layers of particulate matter you incorporate (parameters), the longer it will take water to pass through them all, but you’ll ultimately end up with a higher-quality output.
However, we sometimes hear concerns about how applicable test results from smaller models are to folks planning on running much larger models. A larger model will, of course, be harder to process and take longer to perform inference. But, if the relative performance between GPUs is consistent across model sizes, that would make testing with a smaller model perfectly valid, as it would provide the same insights for how different GPUs compared in terms of LLM performance. In this article, we’d like to explore whether there are meaningful differences between model size and relative performance.

Image
Test Setup
Test Platform
| CPU: AMD Ryzen™ Threadripper™ PRO 7975WX 32-Core |
| CPU Cooler: Asetek 836S-M1A 360mm Threadripper CPU Cooler |
| Motherboard: ASUS Pro WS WRX90E-SAGE SE BIOS Version: 0404 |
| RAM: 8x Kingston DDR5-5600 ECC Reg. 1R 16GB (128GB total) |
| GPUs: NVIDIA GeForce RTX™ 4090 24GB NVIDIA GeForce RTX™ 4080 SUPER 16GB NVIDIA GeForce RTX™ 4080 16GB NVIDIA GeForce RTX™ 3090 24GB Driver Version: 560.70 |
| PSU: Super Flower LEADEX Platinum 1600W |
| Storage: Samsung 980 Pro 2TB |
| OS: Windows 11 Pro 23H2 Build 22631.3880 |
Llama.cpp build 3140 was utilized for these tests, using CUDA version 12.2.0. The models used were Phi-3-Mini-4K-Instruct (3.8B) and Phi3-Medium-4K-Instruct (14B), quantized as Q8_0 (8-bit) GGUFs. Both the prompt processing and token generation tests were performed using the default values of 512 tokens and 128 tokens, respectively, with 25 repetitions apiece, and the results averaged.
GPU Performance
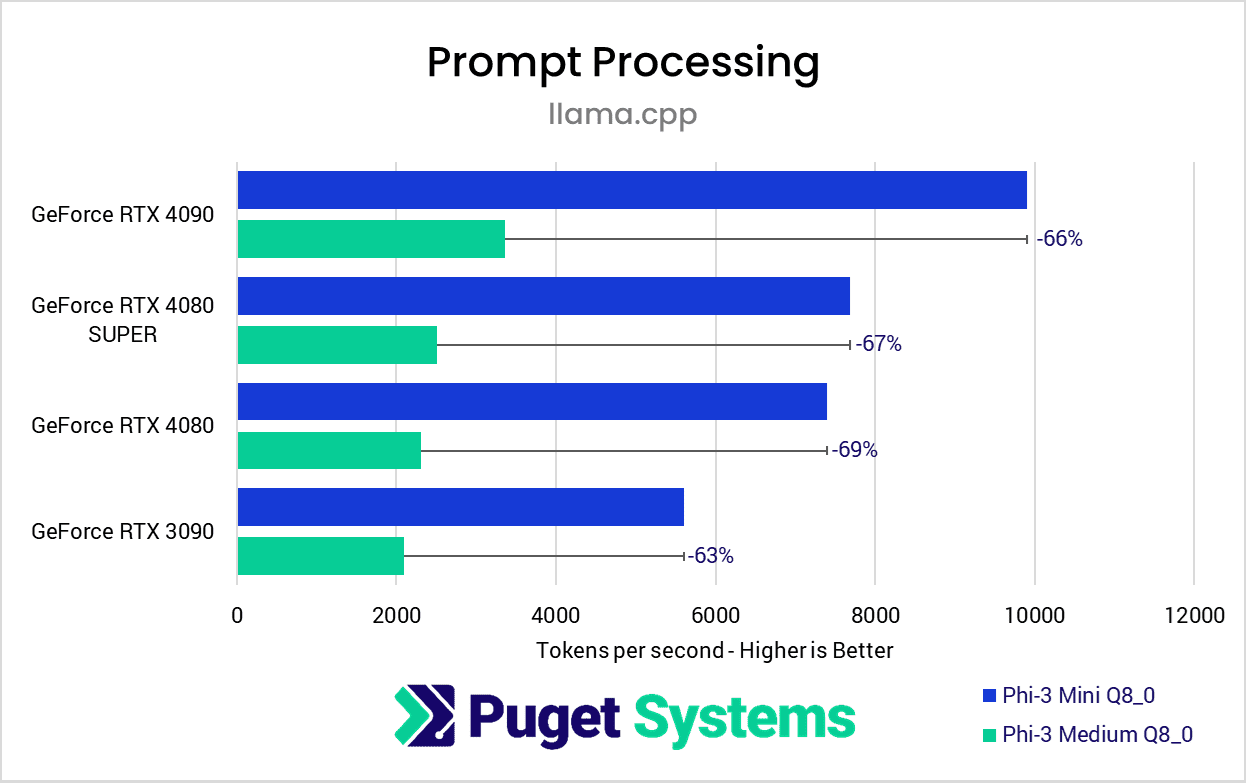
Image
To claim that model size does not change relative performance between GPUs, one needs to demonstrate that the percentage difference does not meaningfully vary between various models. Regrettably, the results from the prompt processing phase of the test aren’t exactly definitive on that point. Although all results are within sub-5% of the median of the scores, the 6% difference between the highest and could potentially be significant.
However, this is still close enough that within a specific product segment, you can get a very good idea of relative performance with a small model like Phi-3 Mini. It is very unlikely that looking at results from a smaller model is going to steer you into making the wrong GPU choice, even if you are working with much larger models.
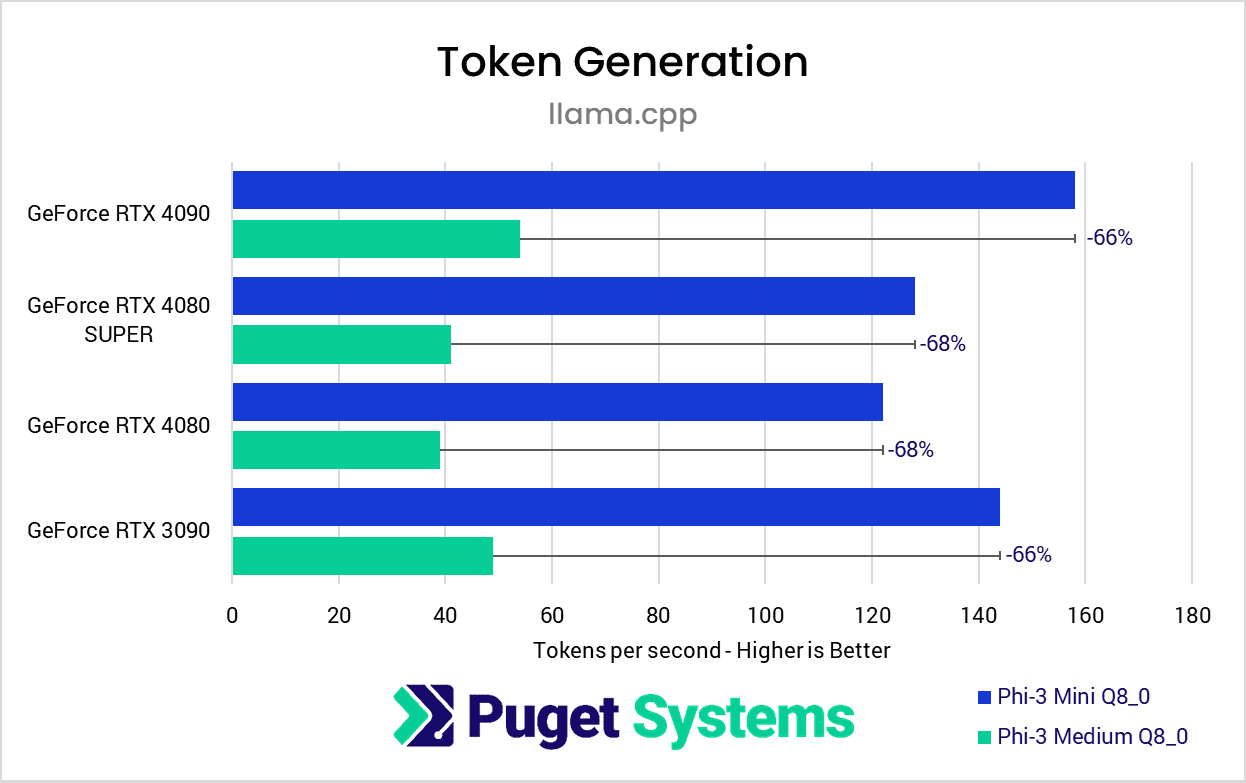
Image
Compared to the prompt processing test, the results from the token generation phase of the benchmark paint a much clearer picture. We recorded a 66% to 68% performance variance across all GPUs tested, which is firmly in favor of the hypothesis that performance scales with model size such that benchmark results from lower parameter count models can be extrapolated to larger model sizes.
Conclusion
When scaling up to more resource-intensive models with larger parameter counts, the impact on performance is consistent across GPU models. In this case, the performance difference between Phi3-mini and Phi3-medium was roughly -66% across all cards tested, leaving the rankings among these cards unchanged by the choice of model used.
In an ideal world, we (and other hardware reviewers) would be able to test with a wide range of models in order to give concrete performance information regardless of what model size the reader plans to use. Unfortunately, the larger the model, the longer it takes to run a benchmark. In addition, larger models often only fit in a handful of different GPU models due to their VRAM requirements, making them unsuited for analysis of GPU performance across an entire product segment.
Occasional testing with larger models may be worth it, but the results we found in this testing give us the confidence to continue using smaller LLMs like Phi3-mini to evaluate GPUs’ relative performance.
Looking for an AI and Scientific Computing workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.