Table of Contents
Introduction
Not long after my recent experience training LoRAs using kohya_ss scripts for Stable Diffusion, I noticed that a new version was released that claimed, “The issues in multi-GPU training are fixed.” This made me interested in giving multi-GPU training a shot to see what challenges I might encounter and to determine what kind of performance benefits could be found.
To do Stable Diffusion training, I like to use kohya-ss/sd-scripts, a collection of scripts to streamline the process, supporting an array of training methods, including native fine-tuning, Dreambooth, and LoRA. bmaltais/kohya_ss adds a gradio GUI to the scripts, which I find very helpful for navigating the myriad of training options instead of a more manual process of discovering, choosing, and inputting training arguments.
With these tools, I want to investigate whether using multiple GPUs is now a viable option for training. And if it does work, how much time could it save compared to a single GPU?
Test Setup
For the most part, I used the same hardware and software configuration we used for the LoRA training analyses. However, I have updated the kohya_ss UI to v22.4.1 and pytorch to 2.1.2. For the GPUs, I used two NVIDIA GeForce RTX 4090 Founder’s Edition cards. I also used the same dataset of thirteen 1024×1024 photos, configured for 40 repeats apiece, for a total of 520 steps in a training run. Also, based on our previous LoRA testing results, I used SDPA cross-attention in all tests.
Additionally, per the scripts’ release notes for 22.4.0, two new arguments are recommended for multi-GPU training:
“--ddp_gradient_as_bucket_view and --ddp_bucket_view options are added to sdxl_train.py. Please specify these options for multi-GPU training.”However, I found that –ddp_bucket_view is not recognized as a valid argument and doesn’t appear anywhere in the code, so I’m not too certain about that statement. On top of that, these arguments were actually added to train_util.py, not sdxl_train.py, and with a nearby comment that states, “TODO move to SDXL training, because it is not supported by SD1/2”. So, it’s unclear to me whether these arguments are only necessary for distributed SDXL training. Ultimately, I did choose to include the –ddp_gradient_as_bucket_view argument.
Also note that all of the training results provided are with full bf16 training enabled, as it was required to complete Dreambooth and Finetuning. Otherwise, they would run out of memory.
Caveats
According to kohya-ss, “In multiple GPU training, the number of the images multiplied by GPU count is trained with single step. So it is recommended to use –max_train_epochs for training same amount as the single GPU training.”
This means that using the same configuration as we would for single GPU training results in twice as many epochs than we have configured. For example, if we expect a single epoch of 1000 steps with a single GPU, then with two GPUs, we would instead get two epochs of 500 steps. This actually doubles the total work because each GPU processes an image during each step, which means the first example is 1000 multiplied by 1 epoch by 1 GPU (1000), while the second is 500 steps by 2 epochs by 2 GPUs (2000).
The simplest way around this is to set max_train_epochs to one, as kohya-ss suggests. Using the example above, this change results in a single epoch with 500 steps. Since each step consists of one image trained per GPU, we can consider these 500 steps equivalent to the 1000 steps of the single GPU training run. In the charts below, I’ve included results from tests performed with max_train_epochs left unconfigured and set to a maximum of one.
However, having the ability to train over multiple epochs and compare them against each other is incredibly helpful for dialing in the resulting output. Therefore, to use multiple epochs without inflating the step count, the training data could instead be prepared with half as many steps per training image, resulting in the same number of total steps as a dataset prepared for training with a single GPU.
I tried training with distributed training optimizations like DeepSpeed and FSDP. However, I could not complete any training runs despite the variety of training configurations I tested, so there may very well be some performance optimizations left on the table if these options are indeed available for these scripts with the correct configuration.
Results
System Image
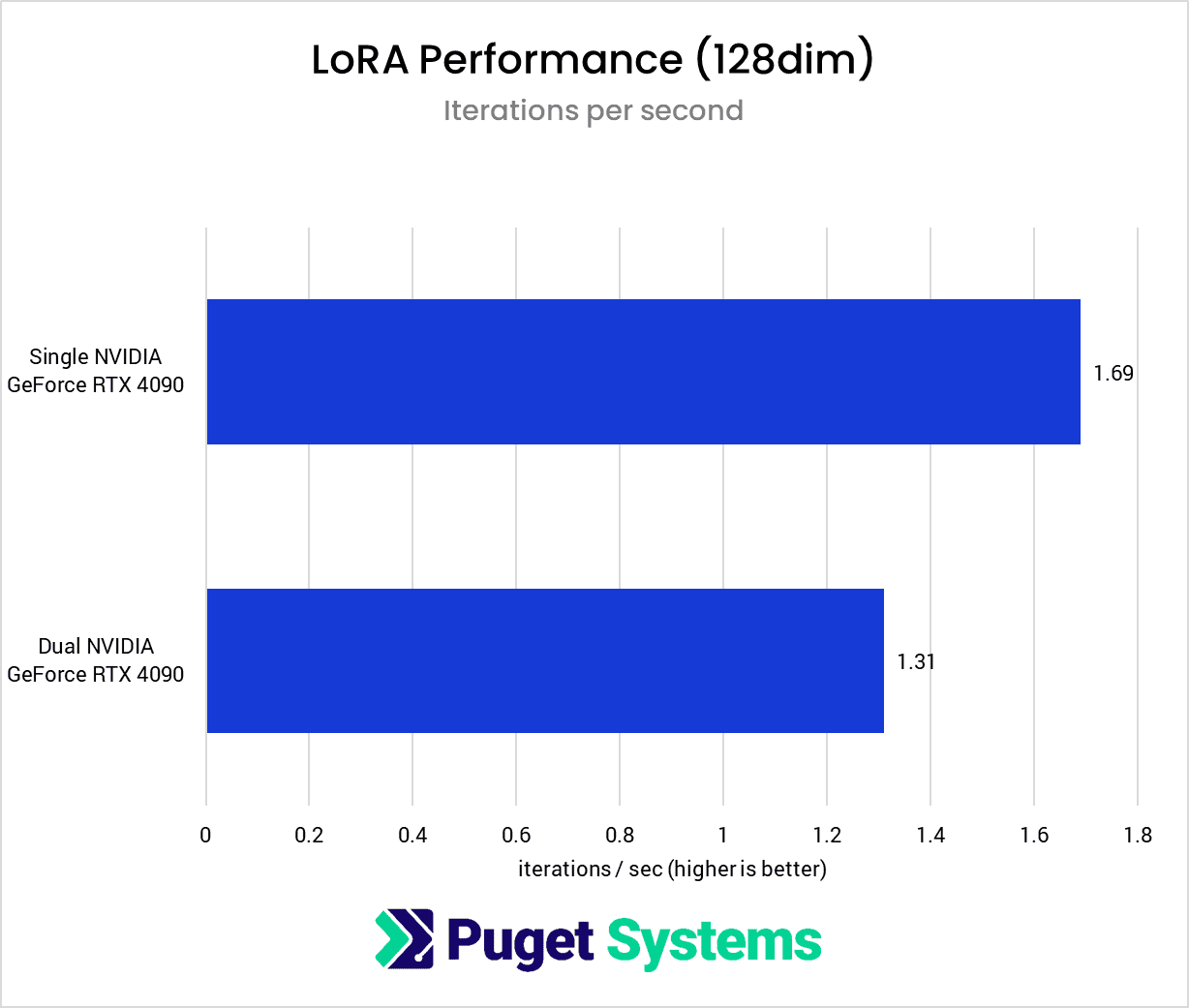
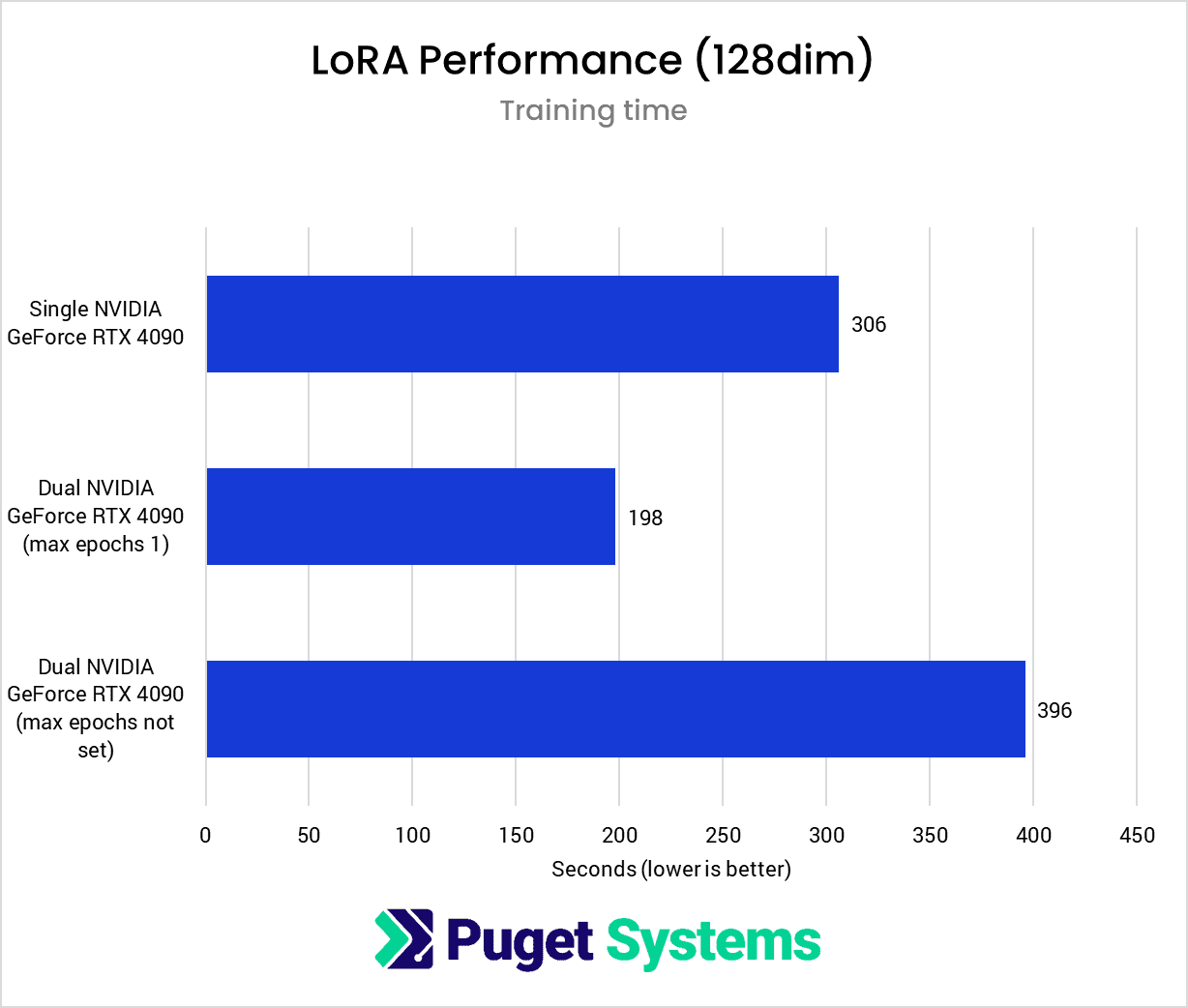
To start off with, we looked at how a second GPU affects performance for training a LoRA with 128 dimensions. Note that we have two charts above, one for iterations per second and another for the total training time. In addition to the single-GPU results, the training time chart has two multi-GPU results to show the difference in total training time between training runs with the maximum epochs uncapped and the maximum epochs limited to one.
It looks like a performance decrease if we only consider the raw iterations per second or the duration of a training run without epochs capped. However, once we set the maximum epochs to one, we can see the performance benefit of training with two GPUs. Although each iteration takes ~23% longer, because we are processing two training images simultaneously, we ultimately complete the training run ~36% faster than with a single GPU.
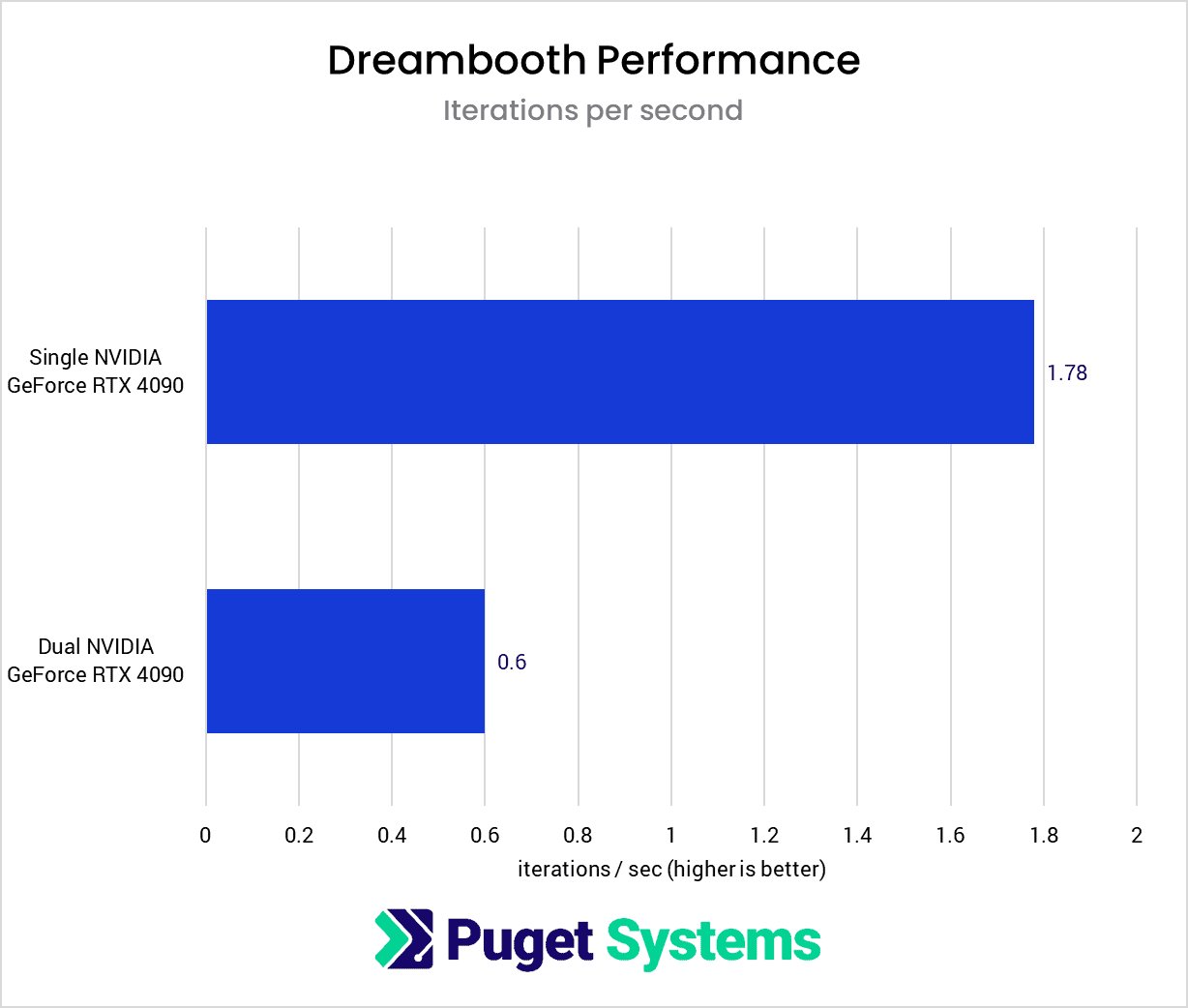
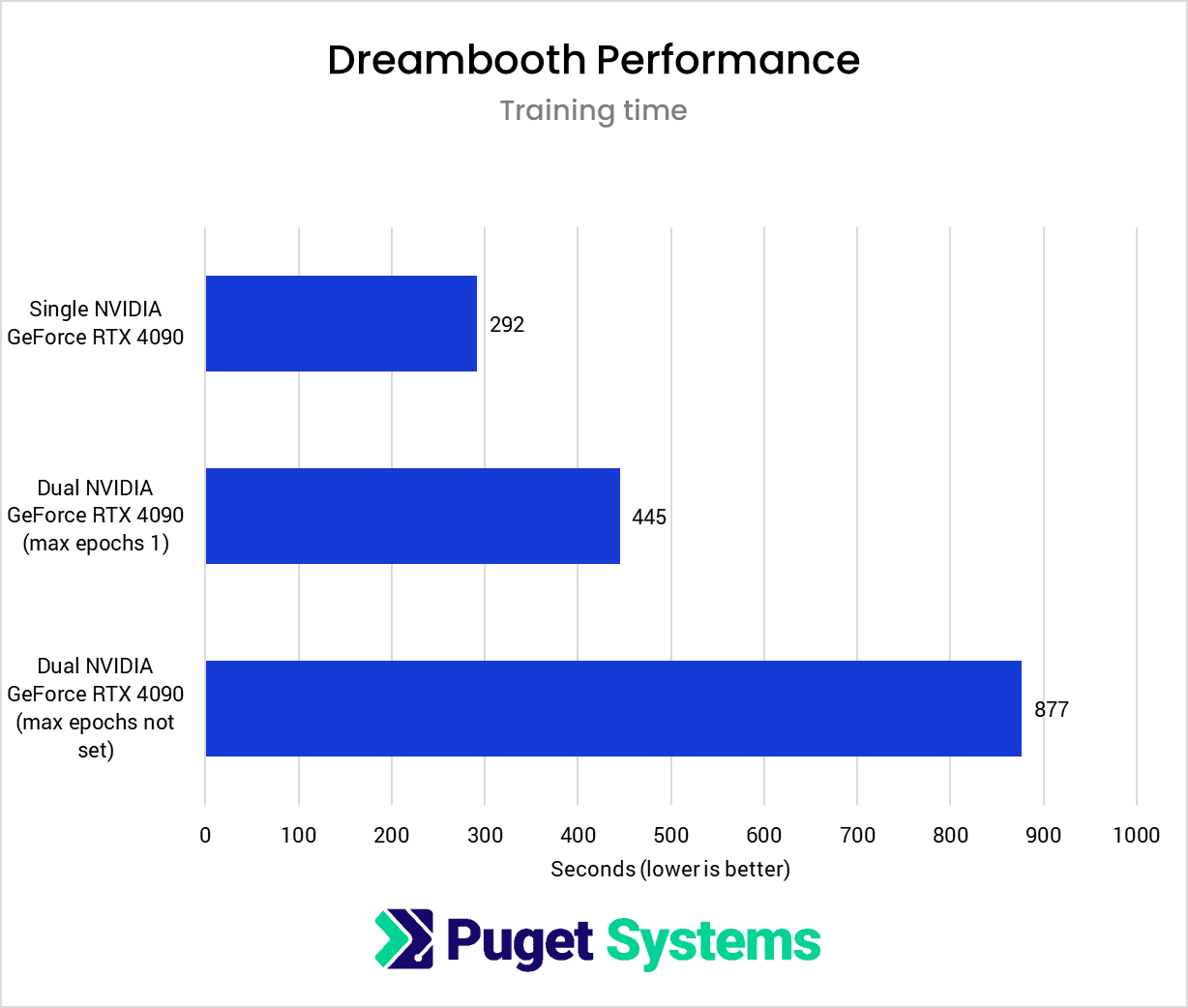
System Image
Unlike the LoRA results, where we saw a moderate performance drop when introducing another GPU, the Dreambooth results show a stark decrease in performance, with the distributed training running at only about one-third of the speed of a single card. Therefore, even after limiting the multi-GPU training run to a single epoch, it’s still insufficient to outperform a single GPU.
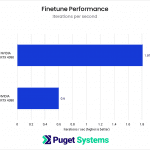
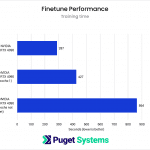
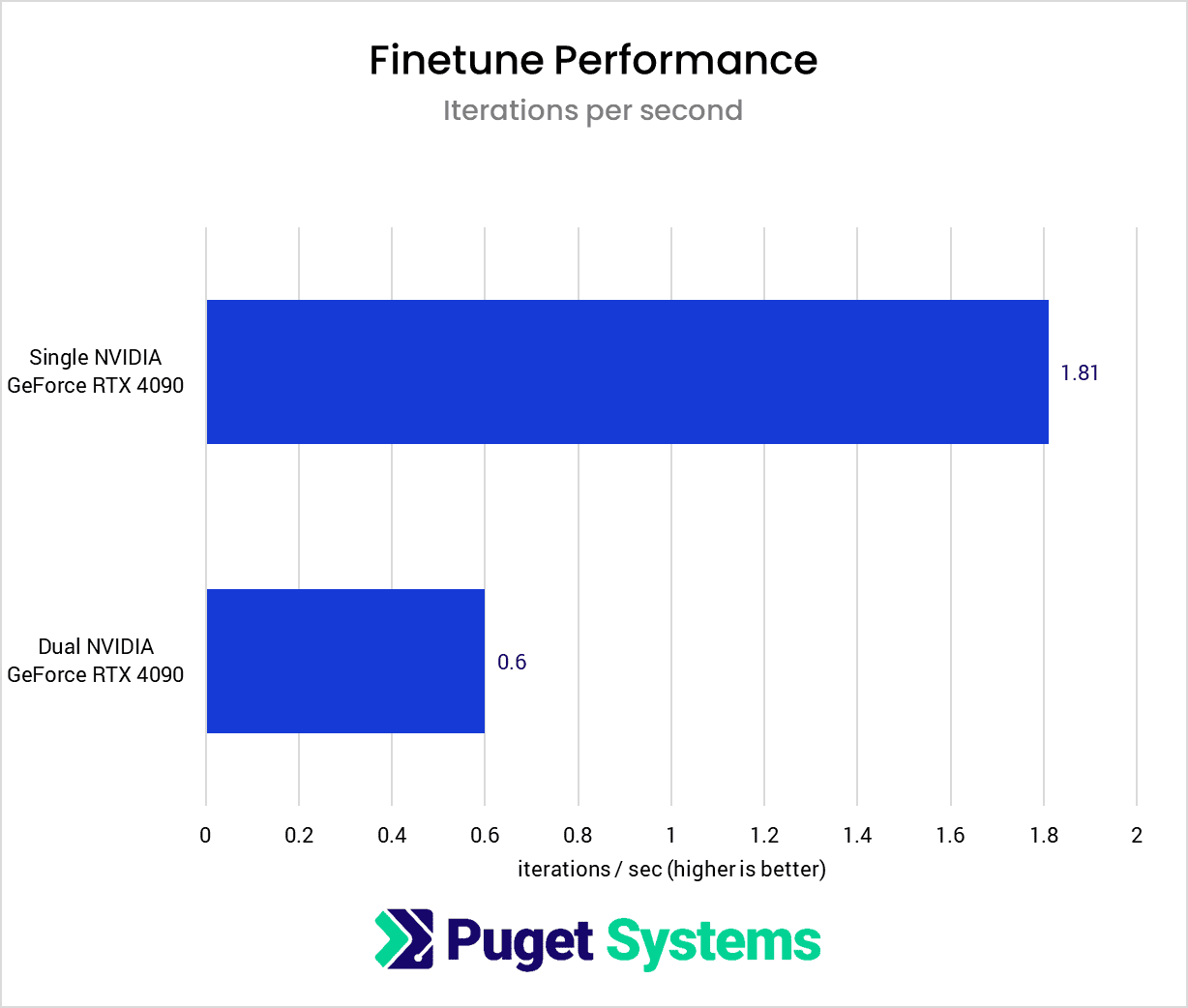
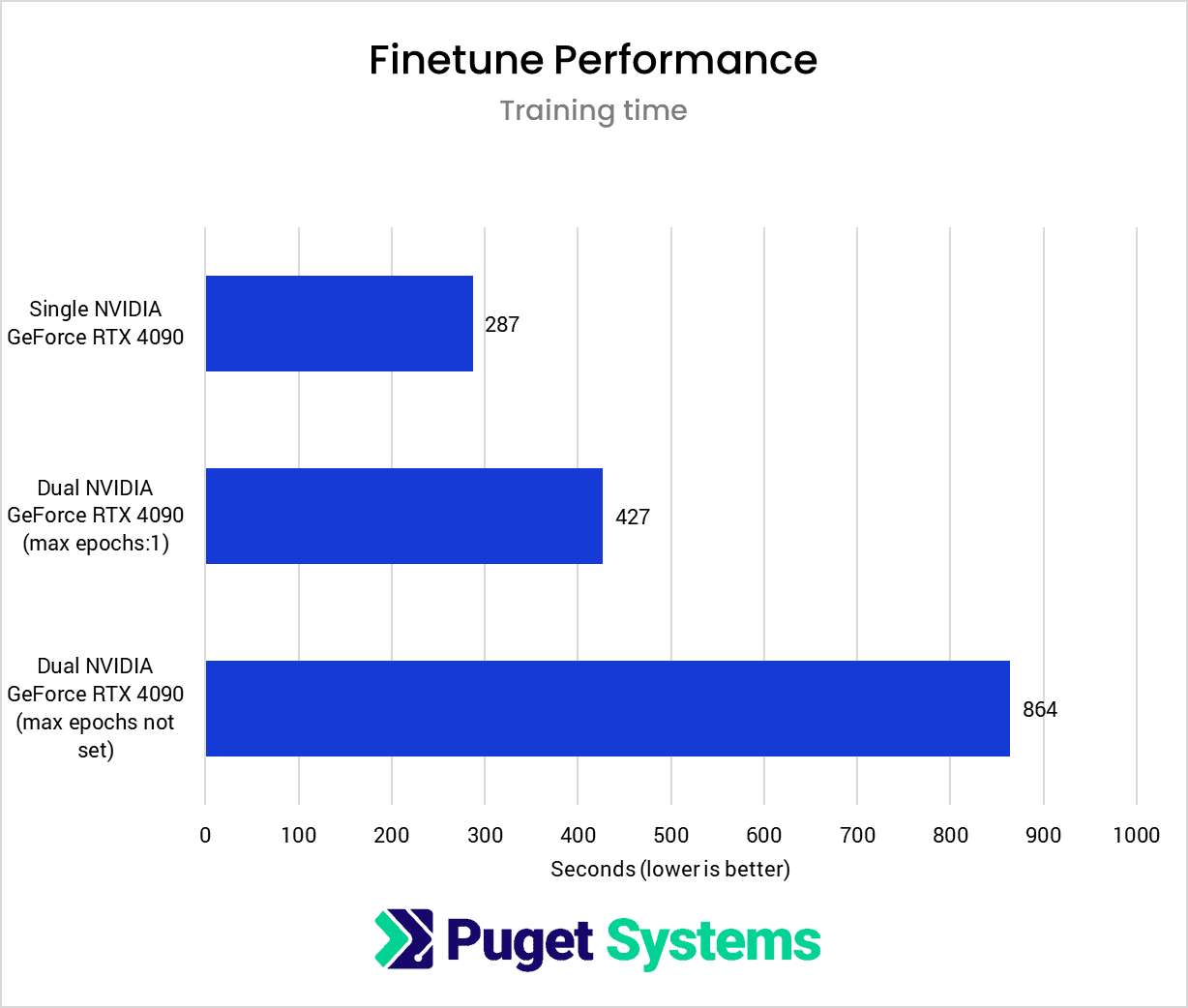
System Image
The finetuning results essentially mirror what I found with Dreambooth. Due to the severe reduction in iterations per second, the simultaneous completion of training steps does not lead to a training time reduction compared to the single GPU training run.
Closing Thoughts
Performance benefits can be achieved when training Stable Diffusion with kohya’s scripts and multiple GPUs, but it isn’t as simple as dropping in a second GPU and kicking off a training run. Beyond configuring Accelerate to use multiple GPUs, we also need to consider how to account for the multiplication of epochs, either by limiting the max epochs to 1 or preparing our dataset with fewer repeats per image.
Furthermore, the only performance benefits I could achieve were with LoRA training, and both Dreambooth and Finetuning had significantly reduced performance. At this point, I’m unsure if this is due to my configuration lacking multi-GPU optimizations such as DeepSpeed or if it is possibly a result of issues with the scripts themselves.
If any readers have successfully utilized DeepSpeed or other distributed training optimizations with kohya’s scripts, I’m eager to hear from you, so please let me know in the comments if you have any advice!
Looking for an AI workstation or server?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.