Table of Contents
Introduction
Over the last few years, NVIDIA has had a stranglehold on the AI and Machine Learning markets, but AMD has been investing a lot of effort into improving support and performance for their Radeon and Radeon PRO GPUs. A great example is a recent BlackMagic DaVinci Resolve update that improved Neural Engine (AI) performance on AMD GPUs by up to 4.5x.
Today, we want to take a look at a Stable Diffusion optimization that AMD recently published for Automatic 1111 (the most common implementation of Stable Diffusion) on how to leverage Microsoft Olive to generate optimized models for AMD GPUs. AMD claims that this can result in performance improvements of up to 9.9x on AMD GPUs, which is something we had to check out for ourselves! What is interesting about this compared to optimizations we have seen from others like NVIDIA is that it is technically a vendor-agnostic solution that can run on any DX12-capable GPUs (including AMD, NVIDIA, and Intel). For developers, this can be a big deal when writing software that is intended to be used by various types of GPU hardware without having to depend on GPU vendor-specific proprietary solutions.
If you want to follow their guide or get additional background on how it works, we recommend reading the post: [UPDATED HOW-TO] Running Optimized Automatic1111 Stable Diffusion WebUI on AMD GPUs.
Image
It is worth noting that AMD is not the only one making performance improvements for Stable Diffusion. NVIDIA also recently released a guide on installing and using a TensoRT extension, which they say should improve performance by almost 3x over the base installation of Automatic 1111, or around 2x faster than using xFormers. This is not as big of a gain as what AMD is touting, but we have a sister article looking at that extension that you can read here: NVIDIA TensorRT Extension for Stable Diffusion Performance Analysis.
While we are primarily looking at the AMD optimizations in this post, we will quickly compare NVIDIA and AMD GPUs at the end of this article using both optimizations to see how each brand compares after everything is said and done.
Test Setup
Threadripper PRO Test Platform
| CPU: AMD Threadripper PRO 5975WX 32-Core |
| CPU Cooler: Noctua NH-U14S TR4-SP3 (AMD TR4) |
| Motherboard: ASUS Pro WS WRX80E-SAGE SE WIFI BIOS Version: 1201 |
| RAM: 8x Micron DDR4-3200 16GB ECC Reg. (128GB total) |
| GPUs: AMD Radeon 7900 XTX 24GB Driver Version: 23.10.2 |
| PSU: Super Flower LEADEX Platinum 1600W |
| Storage: Samsung 980 Pro 2TB |
| OS: Windows 11 Pro 64-bit (22621) |
AMD Ryzen Test Platform
| CPU: AMD Ryzen 9 7950X |
| CPU Cooler: Noctua NH-U12A |
| Motherboard: ASUS ProArt X670E-Creator WiFi BIOS Version: 1602 |
| RAM: 2x DDR5-5600 32GB (64GB total) |
| GPUs: AMD Radeon 7900 XTX 24GB Driver Version: 23.10.2 |
| PSU: Super Flower LEADEX Platinum 1600W |
| Storage: Samsung 980 Pro 2TB |
| OS: Windows 11 Pro 64-bit (22621) |
Benchmark Software
| Automatic 1111 v1.6 DirectML Python: 3.10.6 SD Model: v1.5 |
| Microsoft Olive Optimizations for Automatic 1111 |
| SHARK v20231009.984 SD Model: v1.5 |
We originally intended to test using a single base platform built around the AMD Threadripper PRO 5975WX, but through the course of verifying our results against those in AMD’s blog post, we discovered that the Threadripper PRO platform could sometimes give lower performance than a consumer-based platform like AMD Ryzen or Intel Core. However, Intel Core and AMD Ryzen tended to be within a few percent, so, for testing purposes, it doesn’t matter if we used an AMD Ryzen or Intel Core CPU.
Since it is common for Stable Diffusion to be used with either class of processor, we opted to go ahead and do our full testing on both a consumer- and professional-class platform. We will largely focus on the AMD Ryzen platform results since they tend to be a bit higher, but we will also include and analyze the results on Threadripper PRO.
As noted in the Introduction section, we will be looking specifically at Automatic 1111 and will be testing it in a few different configurations: a base install using the DirectML fork, and an optimized version with Microsoft Olive. In addition, we also wanted to include SHARK since, historically, it is much faster than Automatic 1111 for AMD GPUs. It will be interesting to see if the new optimizations make Automatic 1111 on par, or faster than Shark.
Since changing GPUs requires re-generate the optimized model, we opted to test with just one AMD GPU for now. We decided on the Radeon 7900 XTX, but pro-level cards like the Radeon Pro W7900 should show similar performance uplifts.
For the specific prompts and settings we chose to use, we changed things up from our previous Stable Diffusion testing. While working with Stable Diffusion, we have found that few settings affect raw performance. For example, the prompt itself, CFG scale, and seed have no measurable impact. The resolution does, although since many models are optimized for 512×512, going outside of that sometimes has unintended consequences that are not great from a benchmarking standpoint.
To examine this TensorRT extension, we decided to set up our tests to cover four common situations:
- Generating a single high-quality image
- Generating a large number of medium-quality images
- Generating four high-quality images with minimal VRAM usage
- Generating four high-quality images with maximum speed
To accomplish this, we used the following prompts and settings for txt2img:
Prompt: red sports car, (centered), driving, ((angled shot)), full car, wide angle, mountain road
| txt2img Settings | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Steps | 150 | 50 | 150 | 150 |
| Width | 512 | 512 | 512 | 512 |
| Height | 512 | 512 | 512 | 512 |
| Batch Count | 1 | 10 | 4 | 1 |
| Batch Size | 1 | 1 | 1 | 4 |
| CFG Scale | 7 | 7 | 7 | 7 |
| Seed | 3936349264 | 3936349264 | 3936349264 | 3936349264 |
We will note that we also tested using img2img, but the results were identical to txt2img. For the sake of simplicity, we will only include the txt2img results, but know that they also hold true when using an image as the base input as well.
Looking for a Content Creation Workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with our technical consultants today.
AMD Radeon 7900 XTX Performance Gains
System Image
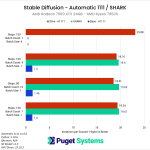
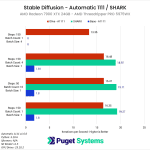
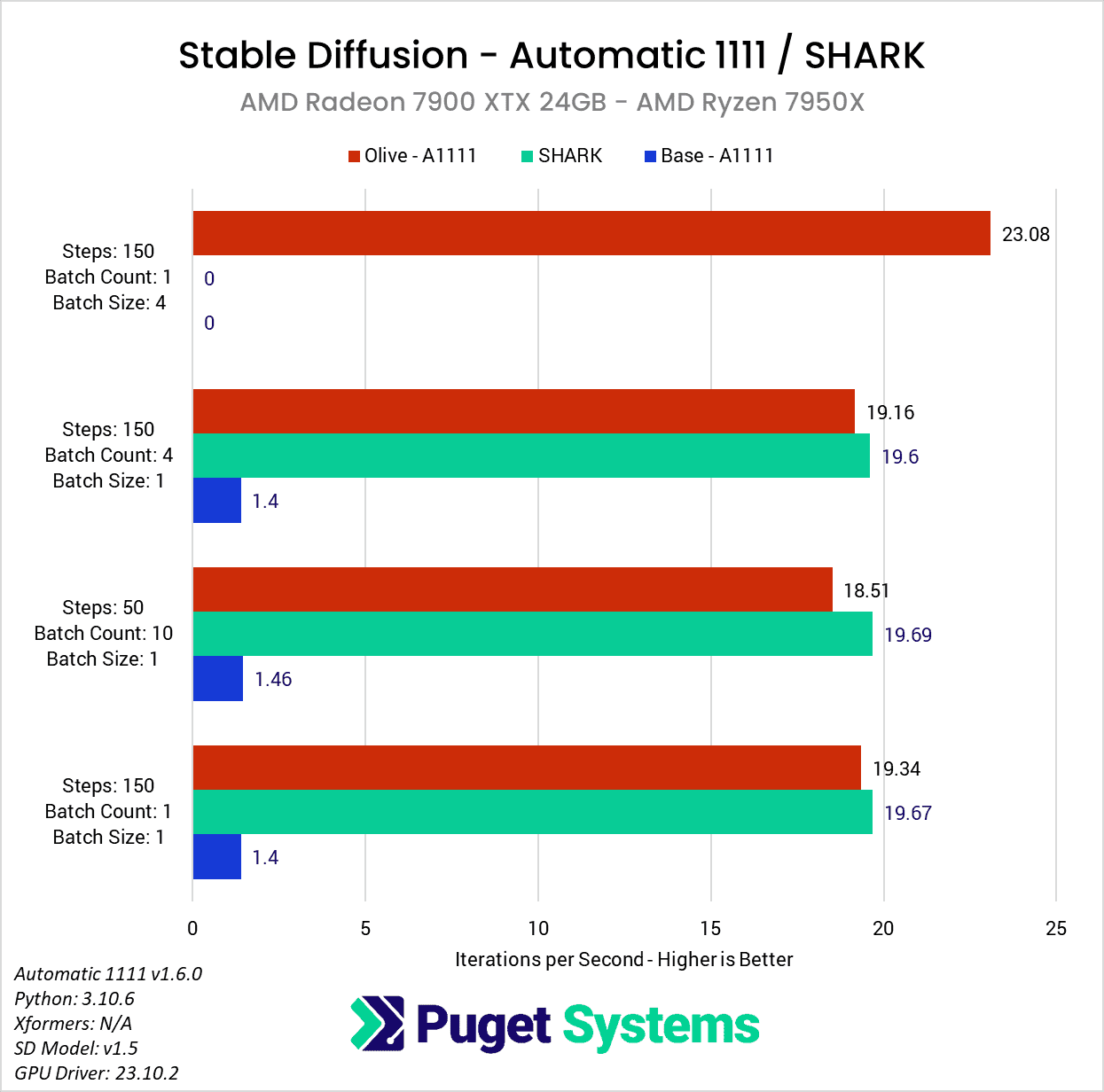
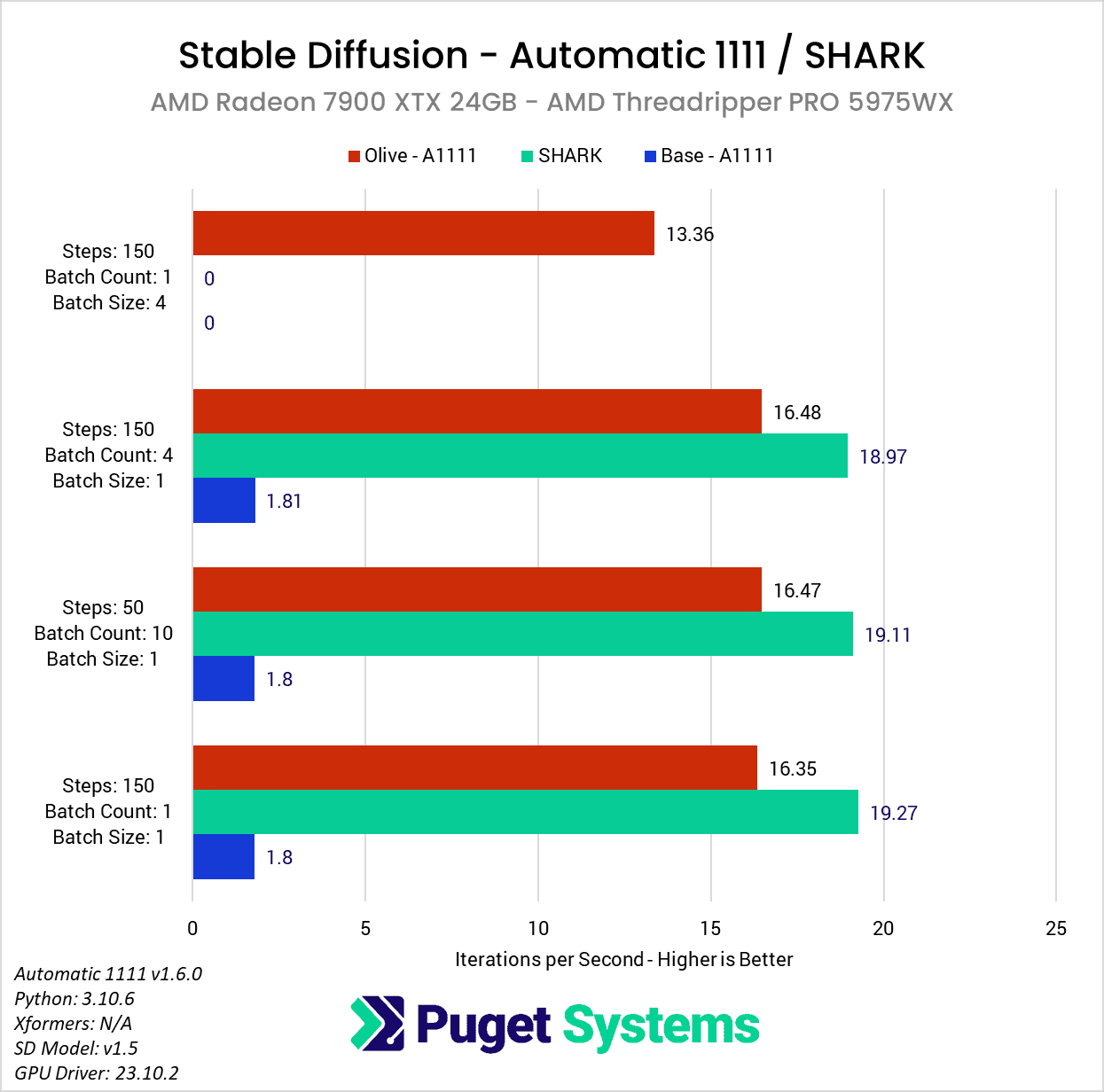
Looking at our results, you may first notice that many of our testing prompts seem a bit redundant. As long as we kept the batch size to 1 (the number of images being generated in parallel), the iterations per second (it/s) are pretty much unchanged with each of the three methods we looked at (Automatic 1111 base, Automatic 1111 w/ Olive, and SHARK). This is expected behavior since this metric essentially reports how many “steps” we can complete each second. In more standard GPU performance testing, we would likely do one of these three tests and call it a day, but we wanted to check to ensure there were no gaps with the optimization. If it turned out to only work with a batch count of 1, or only up to a certain number of steps, that is very important information to have.
The second thing you may notice is that there was a lack of results when we turned the batch size up to four. This setting controls how many images are generated in parallel, increasing performance, but also increasing the amount of VRAM needed. Even though the 7900 XTX has 24GB of VRAM, we ran into issues with insufficient VRAM with the base DirectML fork of Automatic 1111 and SHARK. No amount of –lowVRAM switches could get us around this, but luckily, the Microsoft Olive optimization allowed us to do this test without any special configuration beyond what AMD had in their guide.
This means that unlike in our similar article for NVIDIA, we can’t give you any speedup numbers for larger batch sizes. However, with a batch size of one, we saw some amazing performance gains of about 13.4x versus the base Automatic 1111 install on the AMD Ryzen platform, or about 9.1x on AMD Threadripper PRO. That is roughly in line, or better, than AMD’s example results in their guide.
Even with this massive gain, however, it is only enough to bring Automatic 1111 roughly in line with SHARK. We should also note that this is with the 1.5 Stable Diffusion model, which isn’t installed with SHARK automatically. SHARK defaults to a 2.1 model, which, in our testing is about 20% faster than the 1.5 model. However, comparing different models isn’t great as they work differently and give very different results. We would like to compare Automatic 1111 with a newer model in the future, but we had some issues getting the Microsoft Olive optimizations working on 2.1, so that will have to wait for a future article.
No matter how you look at it, this Microsoft Olive optimization makes a massive difference if you want to use an AMD GPU with Automatic 1111. Across both platforms, we saw on average about an 11.3x increase in performance over a basic Automatic 1111 DirectML installation.
Looking for a Content Creation Workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with our technical consultants today.
Radeon 7900 XTX vs RTX 4080 vs RTX 4090 for Stable Diffusion
While a performance improvement of 11x is a massive accomplishment that will benefit a huge number of users, there remains the question of whether it is enough for AMD to catch up to NVIDIA. It certainly closes the gap significantly, but with NVIDIA also releasing a guide recently for using a TensorRT extension (which we found increased performance by around 2x over xFormers), this is a lot of ground for AMD to cover.
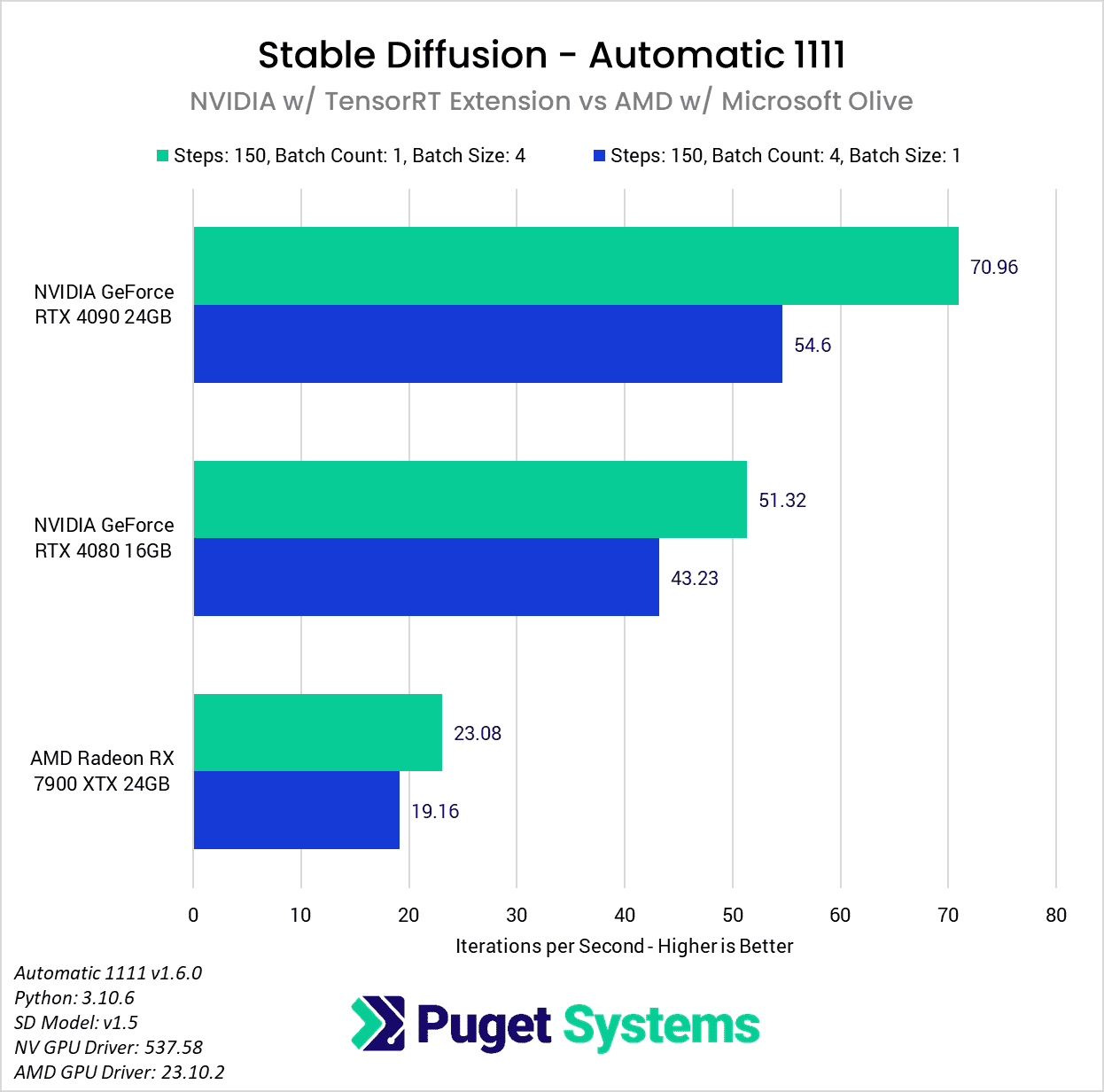
To show how NVIDIA and AMD stack up right now, we decided to take the results from the “Batch Size: 4” and “Batch Count: 4” tests in this article, as well as our NVIDIA-focused article, to show how the RTX 4090, RTX 4080, and Radeon 7900 XTX compare. We will note that this isn’t a completely apples-to-apples comparison since both NVIDIA and AMD are making optimized models or engines for their GPUs, but that seems to be the near reality for this type of workload.
Image
Unfortunately for AMD, even with the huge performance gains we saw in Automatic 1111, it isn’t enough to bring the Radeon 7900 XTX in line with the RTX 4080. Before NVIDIA’s TensorRT extension was available to provide an additional 2x improvement via their custom path, the performance between the 7900 XTX and the RTX 4080 was very similar (23 vs 24 it/s). But, with it, NVIDIA jumps back out into the lead.
AMD has been doing a lot of great things in the AI/ML space recently, and we have hope that optimizations like this are only the tip of the iceberg from AMD. Olive is interesting because it is vendor-agnostic, so it should work on AMD, Intel, and NVIDIA GPUs; unlike NVIDIA’a TensorRT extension that only works on their GPUs. It also isn’t limited only to Automatic 1111. If it can be implemented by SHARK, we could see AMD jump right back to being on par with NVIDIA.
However, for the moment, with the current optimizations recommended by both NVIDIA and AMD we are still looking at about 2.2x higher performance with an NVIDIA GeForce RTX 4080 over the AMD Radeon 7900 XTX, or 3x higher performance with a more expensive RTX 4090.
Conclusion
The world of Artificial Intelligence and Machine Learning is in constant flux, in part because everyone is looking for ways to expand what it can do, and how fast it can be done. This Microsoft Olive optimization for AMD GPUs is a great example, as we found that it can give a massive 11.3x increase in performance for Stable Diffusion with Automatic 1111.
This huge gain brings the Automatic 1111 DirectML fork roughly on par with historically AMD-favorite implementations like SHARK. It isn’t enough for AMD to catch up to NVIDIA in terms of raw performance for Stable Diffusion (yet), but it shows how much can still be gained through pure software optimizations. While we don’t expect an 11x performance increase like this to be common, we are excited to see what AMD can do in the future. If nothing else, we are looking forward to what this may be able to do if implemented in other Stable Diffusion solutions like SHARK.
If you use Stable Diffusion on an AMD GPU, we would be very interested to hear about your experience with the Microsoft Olive optimations in the comments! And if you are looking for a workstation for any Content Creation workflow, you can visit our solutions pages to view our recommended workstations for various software packages, our custom configuration page, or contact one of our technology consultants for help configuring a workstation that meets the specific needs of your unique workflow.
Looking for a Content Creation workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.