Table of Contents
Introduction
Developing and fine-tuning AI models can be a resource-intensive process, often requiring numerous powerful graphics cards working together in a large data center. An alternative approach to training new models from scratch or adjusting all parameters of an existing model is known as Low-Rank Adaptation (LoRA). LoRA involves fine-tuning models with a significantly reduced set of parameters, resulting in a more efficient process that requires only a fraction of the resources previously needed.
As promised in our recent article where we compared the performance of a variety of Pro-level GPUs, we have continued our LoRA testing, this time focusing on a number of consumer-level GPUs. LoRAs are a popular way of guiding models like SD toward more specific and reliable outputs. For instance, instead of prompting for a “car” and receiving whatever SD’s idea of a car’s characteristics includes, you could include a LoRA trained on images of a “DeLorean” to output images of cars that reliably mimic the features of that specific vehicle.
Depending on the size of your dataset, training a LoRA can still require a large amount of compute time, often hours or potentially even days. In addition, it can require large amounts of VRAM depending on the settings you use, which makes Professional GPUs like the NVIDIA RTX cards ideal if it is something you do a lot. However, if you are just testing things out, or otherwise are not investing in that class of card, then even though their VRAM capacity is more limited, and they aren’t designed for heavy sustained loads, a consumer GPU (like NVIDIA GeForce) can absolutely get the job done.

Image
In this article, we will be examining both the performance and VRAM requirements when training a standard LoRA model for SDXL within Ubuntu 22.04.3 using kohya_ss training scripts with bmaltais’s GUI. Although there are many more options available beyond standard LoRAs, such as LoHa, LoCon, iA3, etc, we’re more interested in measuring a baseline for performance, rather than optimizing for filesize, fidelity, or other factors. This also means that we won’t be focusing on the various settings that impact the behavior of the final product but don’t impact performance during training, such as learning rates.
Test Setup
Threadripper PRO Test Platform
| CPU: AMD Threadripper PRO 5995WX 64-Core |
| CPU Cooler: Noctua NH-U14S TR4-SP3 (AMD TR4) |
| Motherboard: ASUS Pro WS WRX80E-SAGE SE WIFI BIOS Version: 1201 |
| RAM: 8x Micron DDR4-3200 16GB ECC Reg. (128GB total) |
| GPUs: AMD Radeon RX 7900 XTX Driver Version: 6.2.4-1683306.22.04 NVIDIA GeForce RTX 4090 NVIDIA GeForce RTX 4080 NVIDIA GeForce RTX 3090 NVIDIA GeForce RTX 2080 Ti Driver Version: 535.129.03 |
| PSU: Super Flower LEADEX Platinum 1600W |
| Storage: Samsung 980 Pro 2TB |
| OS: Ubuntu 22.04.3 LTS |
Benchmark Software
| Kohya’s GUI v22.2.1 Python: 3.10.6 SD Model: SDXL AMD: PyTorch 2.1.1 + ROCm 5.6 NVIDIA: PyTorch 2.1.0 + CUDA 12.1 xFormers 0.0.22.post7 |
| Optimizer: Adafactor Arguments: scale_parameter=False, relative_step=False, warmup_init=False |
| Other arguments: network_train_unet_only, cache_text_encoder_outputs, cache_latents_to_disk |
By and large, we are still using the same test setup as we did previously, both in terms of the test bench hardware and the software & driver versions. And just like our previous testing, we will be training an SDXL LoRA with the base model provided by StabilityAI using a set of thirteen photos of myself, without regularization images or captions.
However, in contrast to our previous professional GPU testing, we will also be including results of testing performed with gradient checkpointing enabled along with testing performed upon a version of the dataset with images that have been scaled down to 512×512. This is due to the VRAM limitations we encountered as a result of the selection of GPUs included in this round of testing. Gradient checkpointing can significantly reduce VRAM usage, but it comes with a notable performance loss.
Following recommendations for SDXL training, we enabled the following settings: network_train_unet_only, cache_text_encoder_outputs, cache_latents_to_disk
Thankfully, these options not only save some VRAM but also improve training speed as well.
Because we found that the reported speeds and VRAM usage leveled out after a couple of minutes of training and additional epochs yielded identical results, we chose to test each GPU with 1 epoch of 40 steps per image, for a total of 520 steps using a batch size of 1.
Finally, we used the Adafactor optimizer with the following arguments: scale_parameter=False, relative_step=False, warmup_init=False
Looking for an AI Workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with our technical consultants today.
Performance – 1024×1024
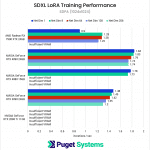
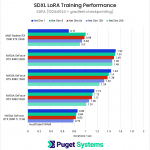
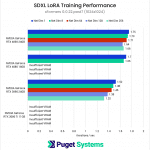
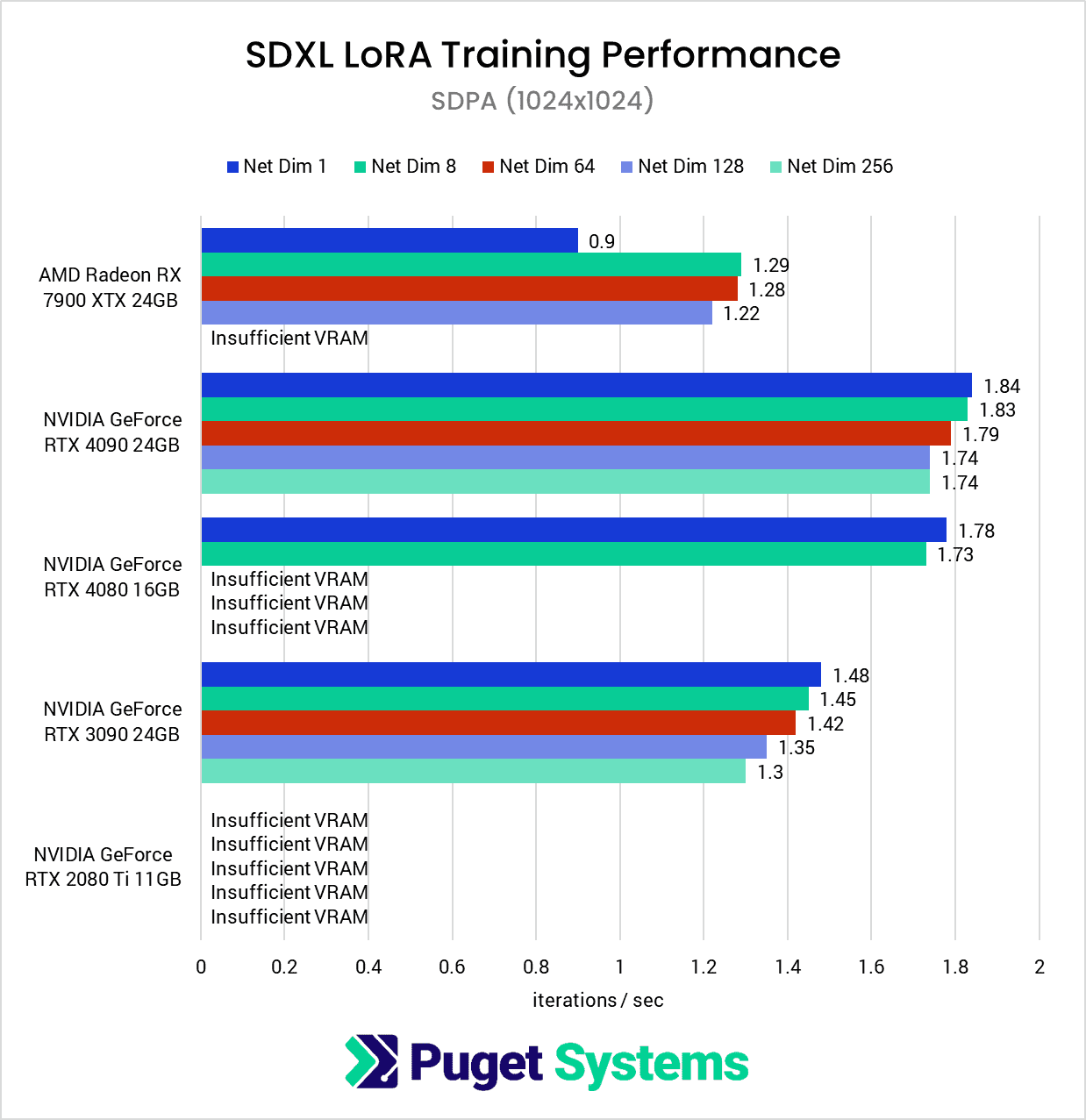
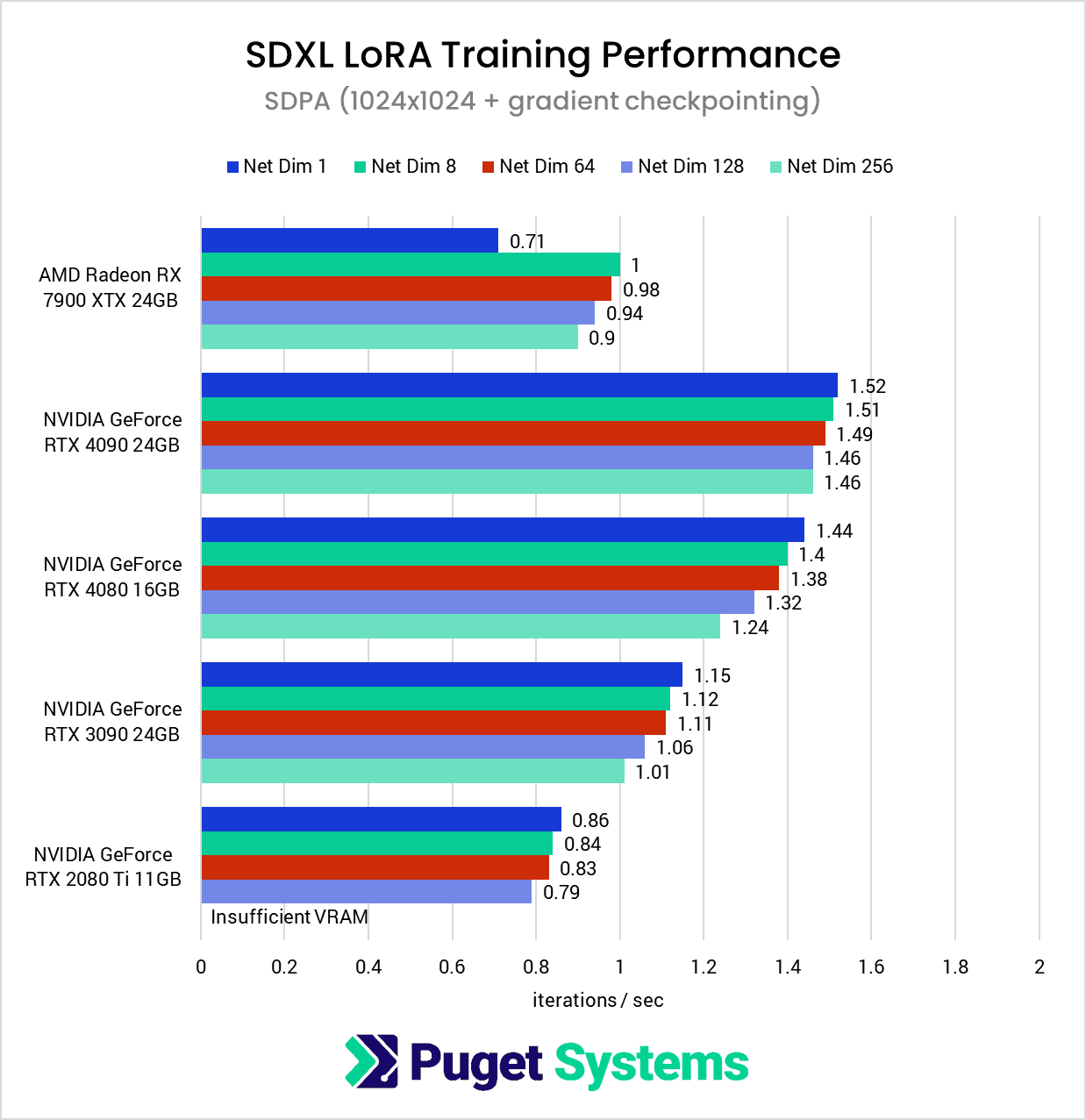
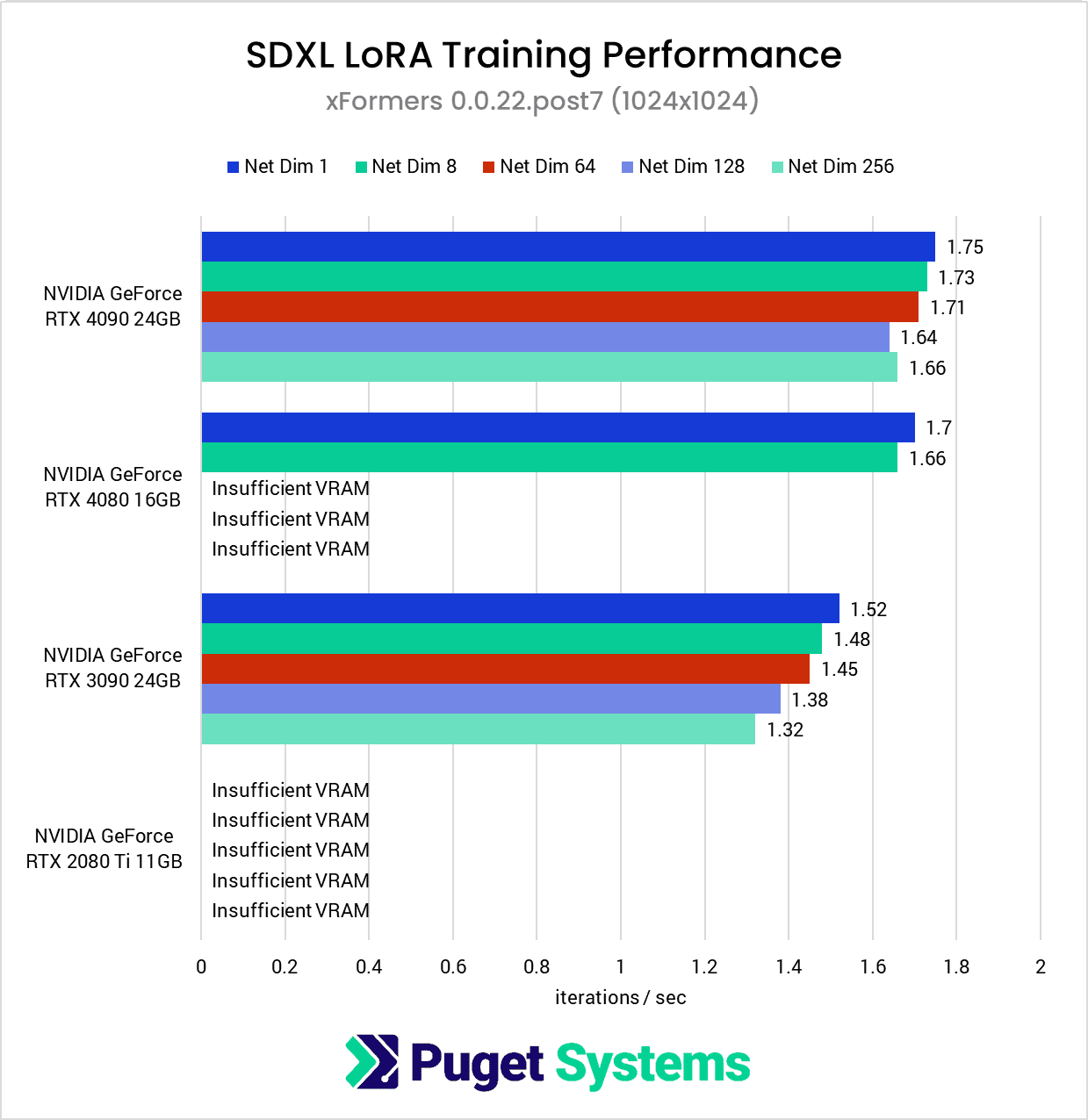
The first chart is a perfect example of why we expanded the testing parameters used during this round. Due to VRAM limitations, the only GPUs that were able to complete the entire suite of tests were the RTX 4090 and RTX 3090.
Just as we saw with the Radeon PRO W7900, we found that the Radeon RX 7900 XTX struggled at Network Dimension 1, despite all of the NVIDIA GPUs producing their highest scores at that setting. We still don’t have a great explanation, but this at least confirms that it is an AMD-wide issue, and not something specific to a single model, or a hardware issue with one of our cards.
Furthermore, we found that the patterns between SDPA and xFormers performance (chart #3) held true during this round of testing as well: the Ada-generation cards perform better using SDPA, while the older generations perform slightly better with xFormers.
The second chart introduces the first results using gradient checkpointing, which reduced the VRAM requirements enough to allow all of the tests to be completed, except for the 256-dimension test for the 2080 Ti. We can see that, with gradient checkpointing enabled, performance decreased by about 22% for both the Radeon RX 7900 XTX and the RTX 3090, while the RTX 4090’s performance dropped by about 17%.
The big takeaway here is that if you want to train a LoRA at 1024×1024, the two key factors to get the best performance are: to get as much VRAM as you can (at least 24GB) and, for now, to stick with NVIDIA over AMD.
VRAM Usage – 1024×1024
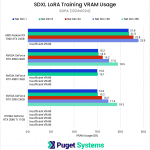
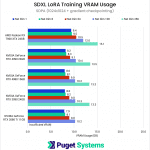
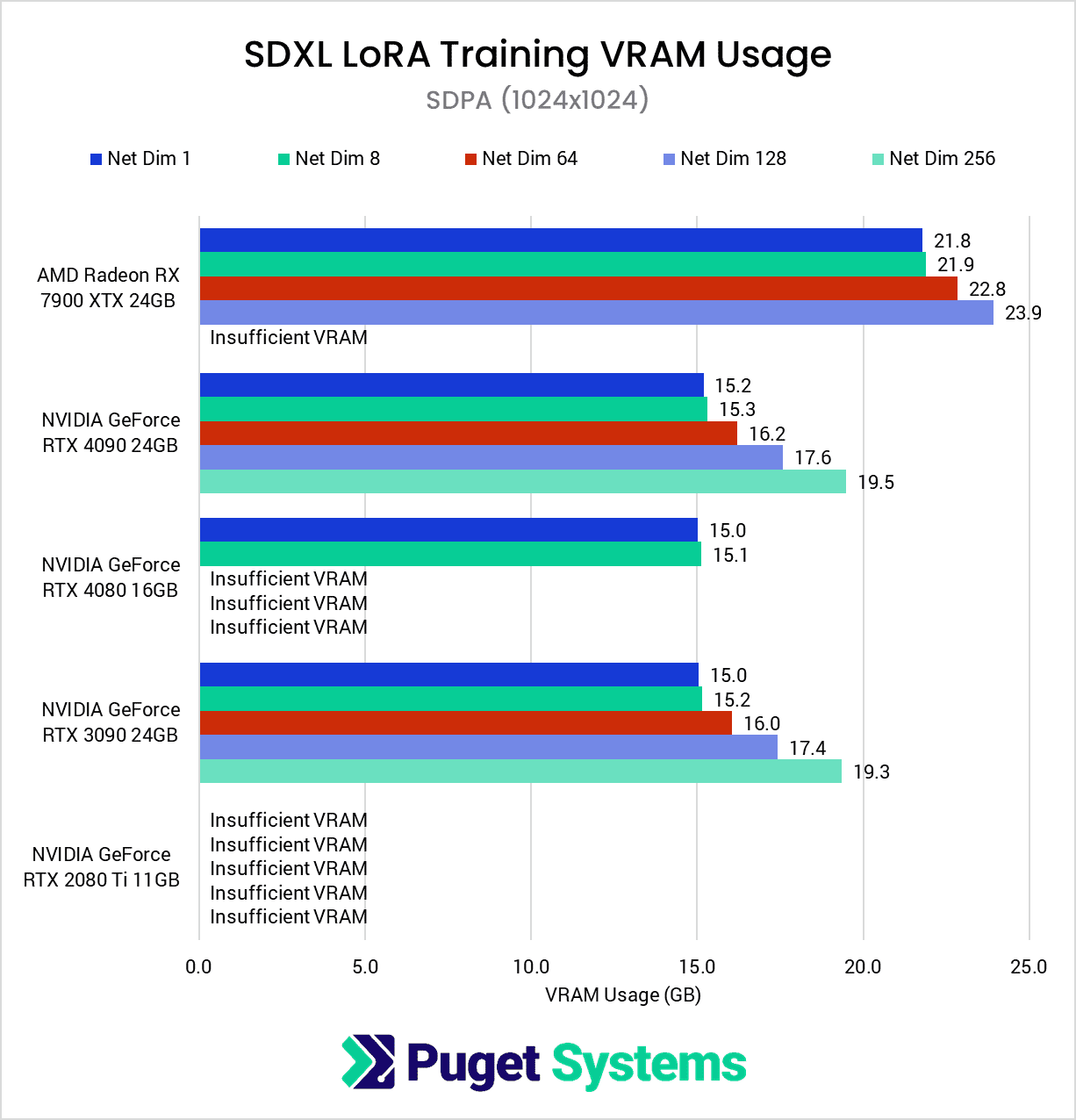
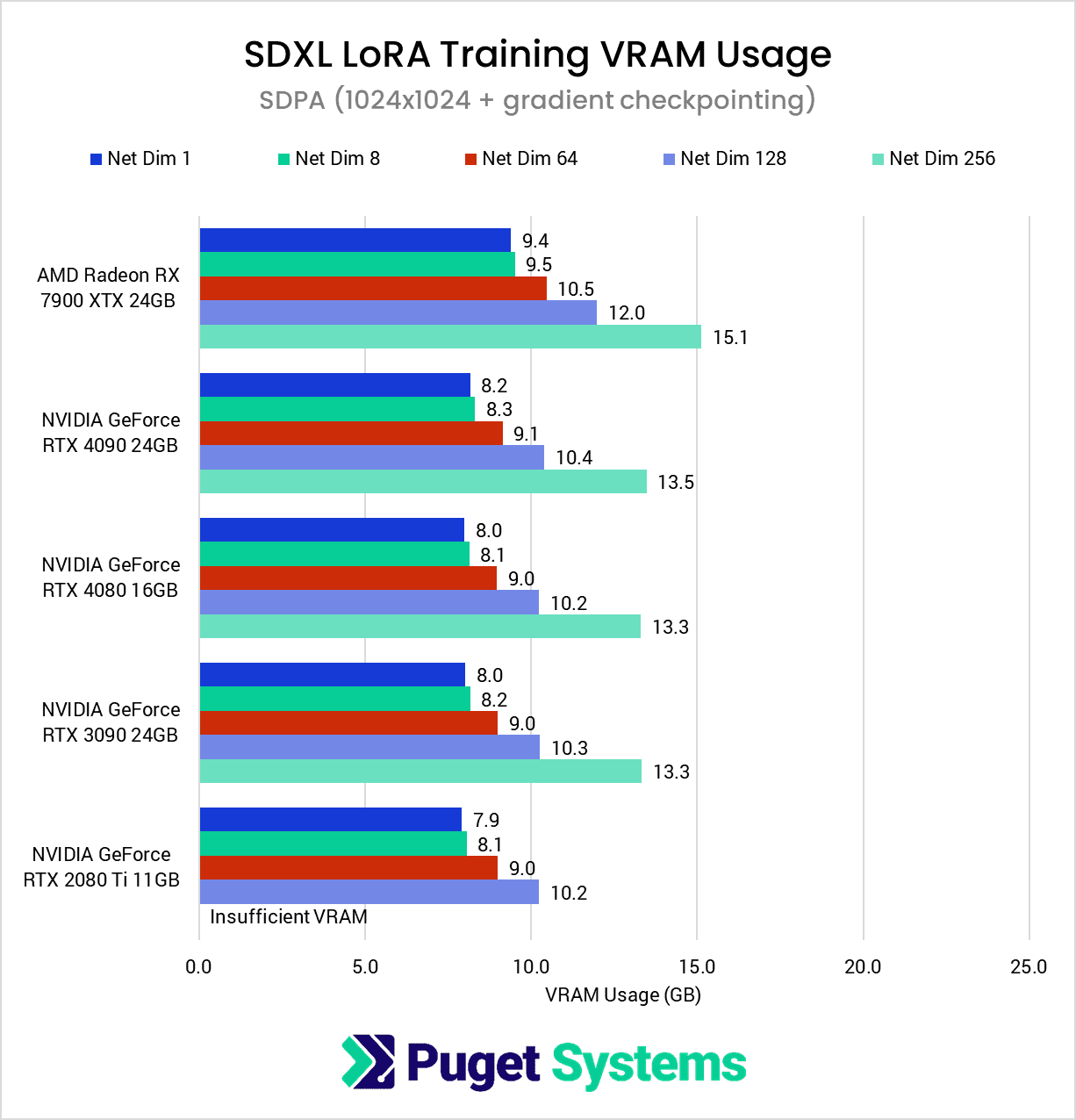
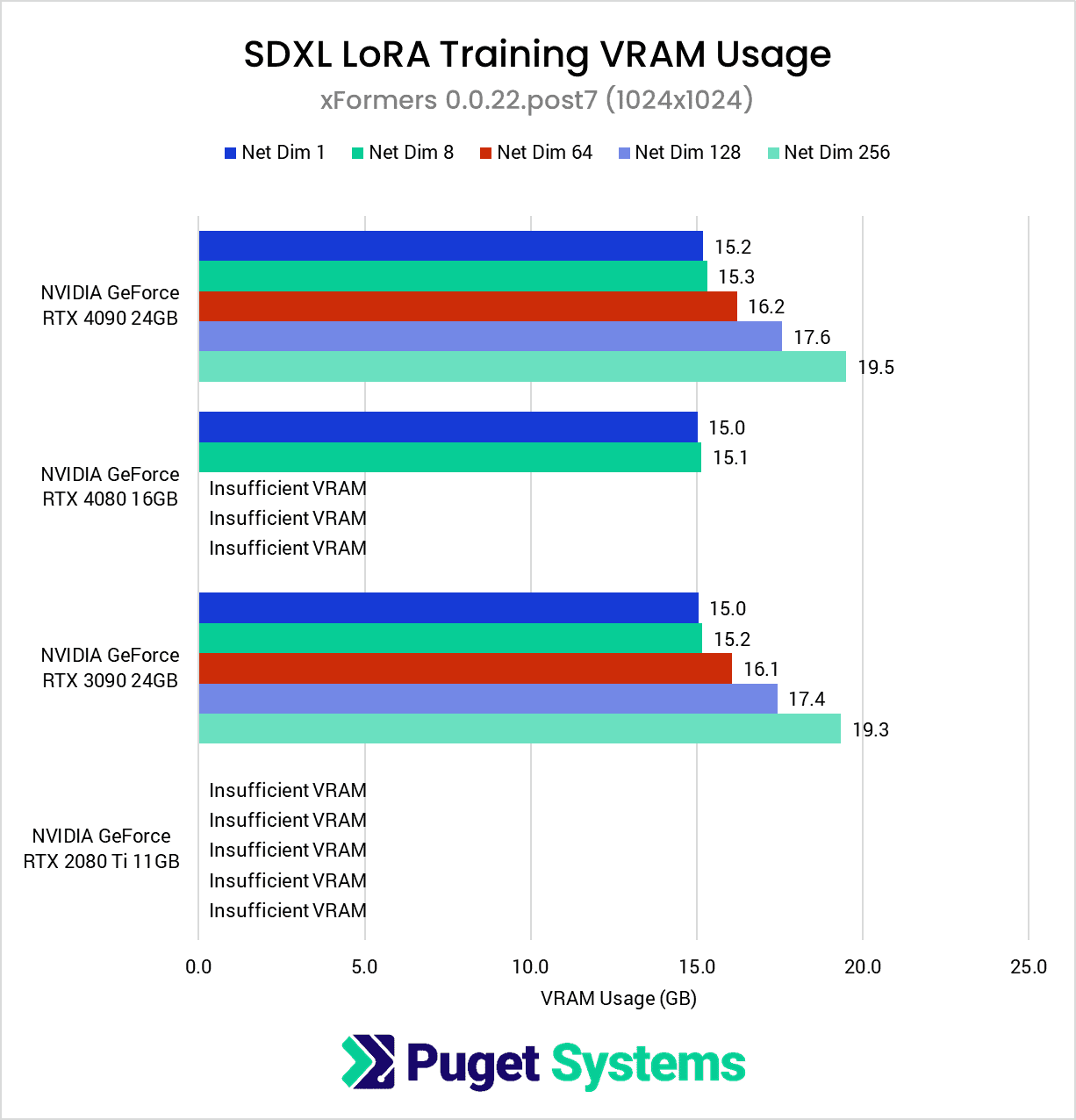
Diving into the VRAM usage, just as we saw with the Radeon PRO W7900, we found that the Radeon RX 7900 XTX had much higher VRAM usage compared to its NVIDIA counterparts. This prevented the 256-dimension test from completing successfully, despite it having 24GB just like the RTX 4090 and RTX 3090.
However, we can see that with gradient checkpointing enabled (chart #2), VRAM requirements drop by an impressive 30-50%, enabling even the 11GB RTX 2080 Ti to participate in all but the 256-dimension test.
As in our previous article, we did not find a significant difference in SDPA and xFormers VRAM usage.
Performance – 512×512
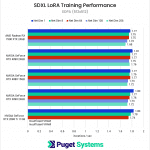
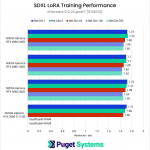
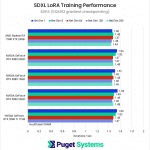
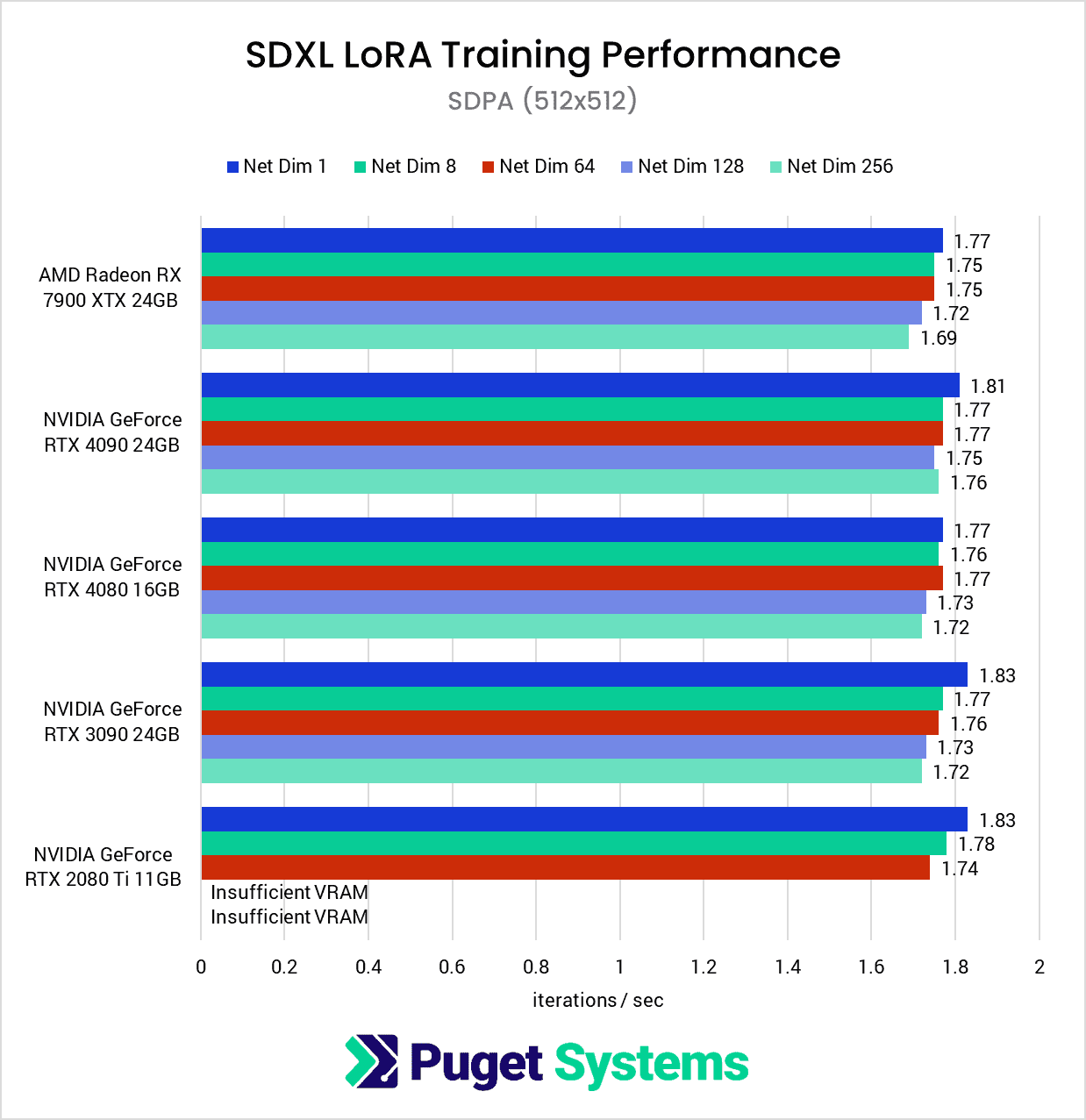
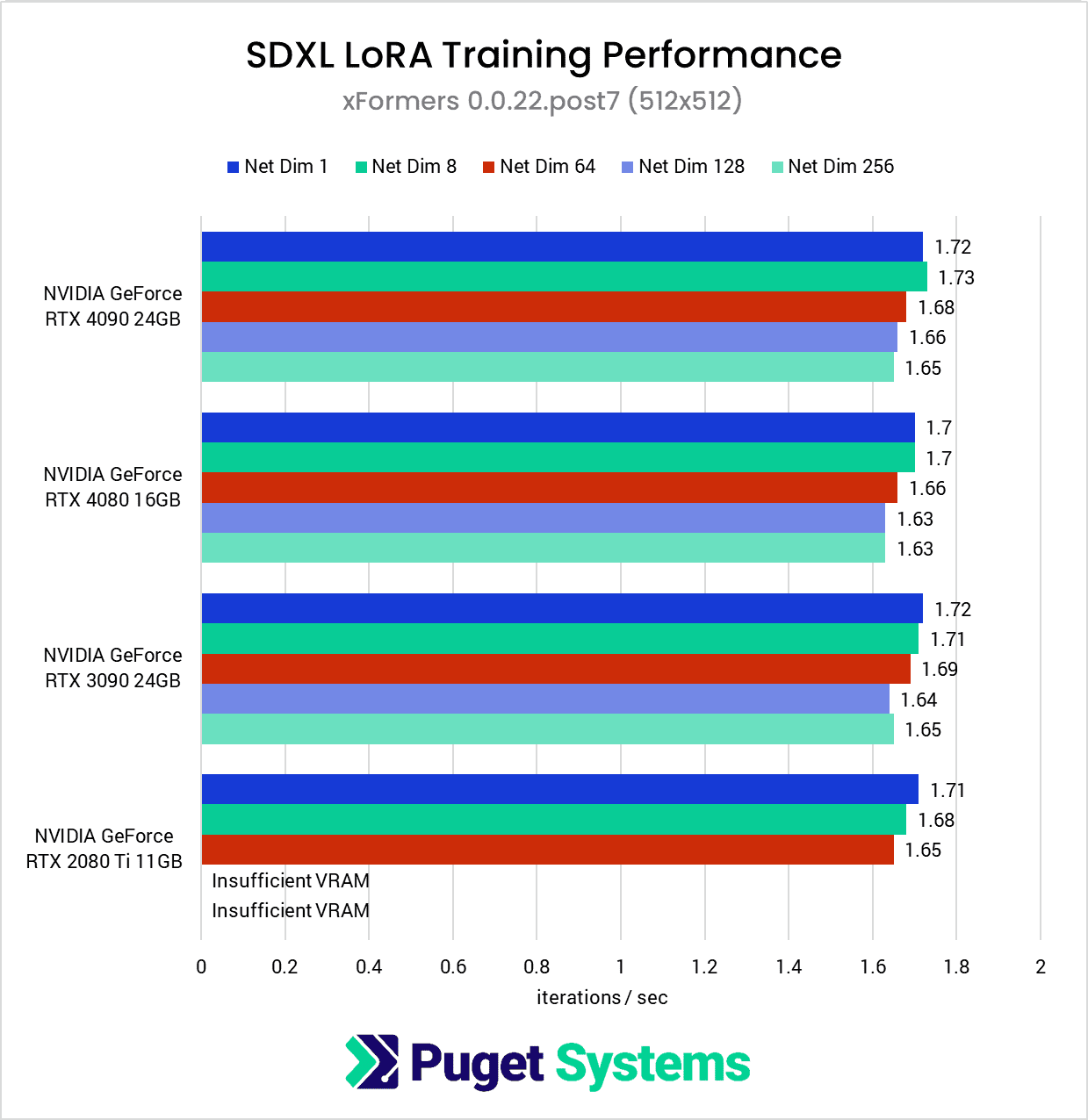
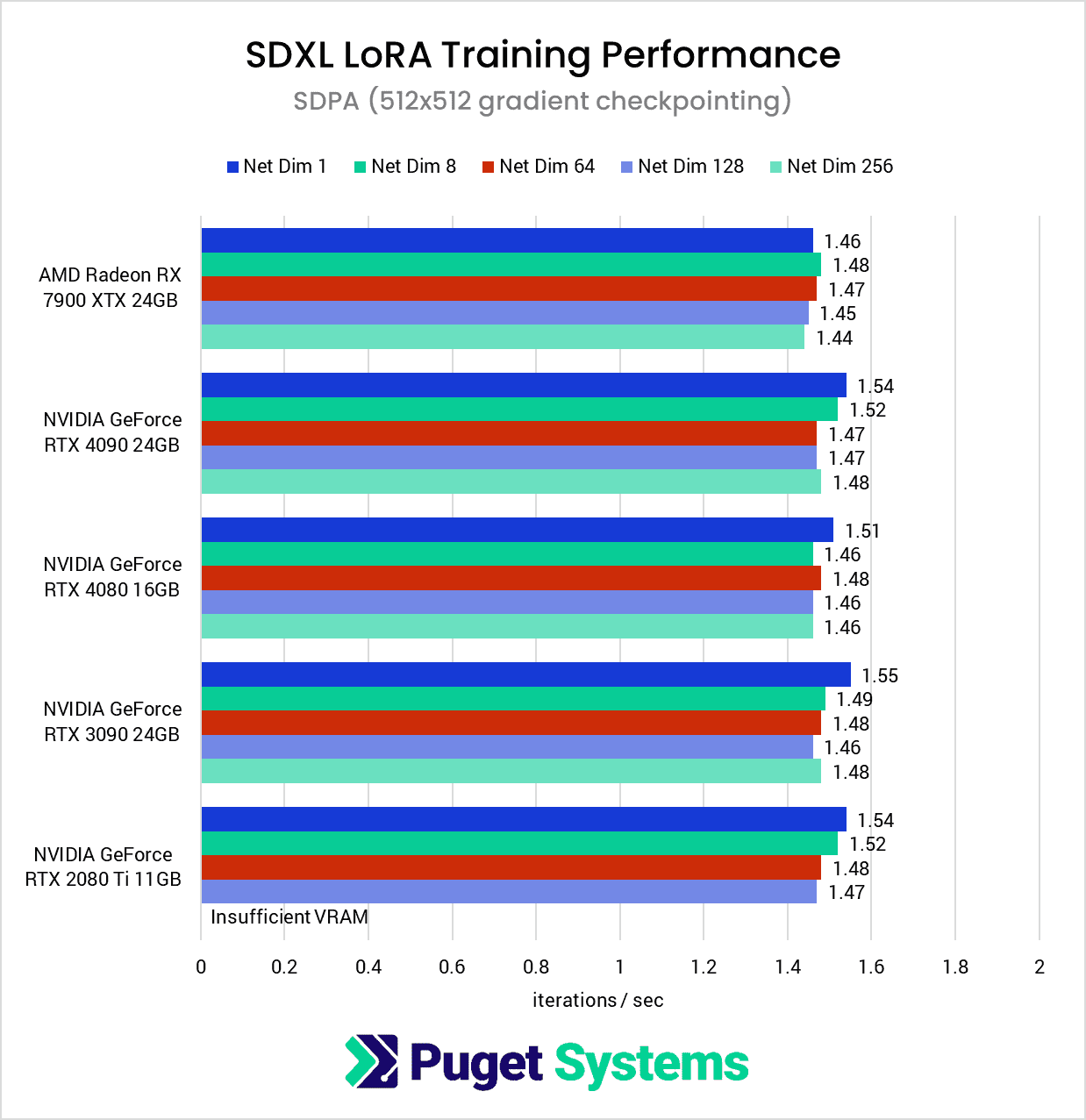
As we mentioned at the start of this article, due to the lower VRAM capacities on these consumer GPUs, we opted to expand our testing to include a lower-resolution version of the dataset, which produces some interesting results. Right off the bat, we see the elimination of the poor Network Dimension 1 performance we’ve seen so far with the AMD GPUs we’ve tested.
At this lower resolution, it’s difficult to make meaningful comparisons because the performance numbers using the 512×512 dataset are nearly identical across all of the GPUs tested.
This is a bit strange since you would expect an RTX 4090 to beat the much older RTX 2080 Ti, and this indicates that we are likely looking at a bottleneck elsewhere in the system or software. Since we are using a powerful 64-core Threadripper PRO processor with 8 channels of RAM, this is likely to be the same bottleneck any other user would run into as well.
In other words, if you are only training LoRAs with 512×512 images, getting a faster GPU is likely to make a surprisingly small difference in performance.
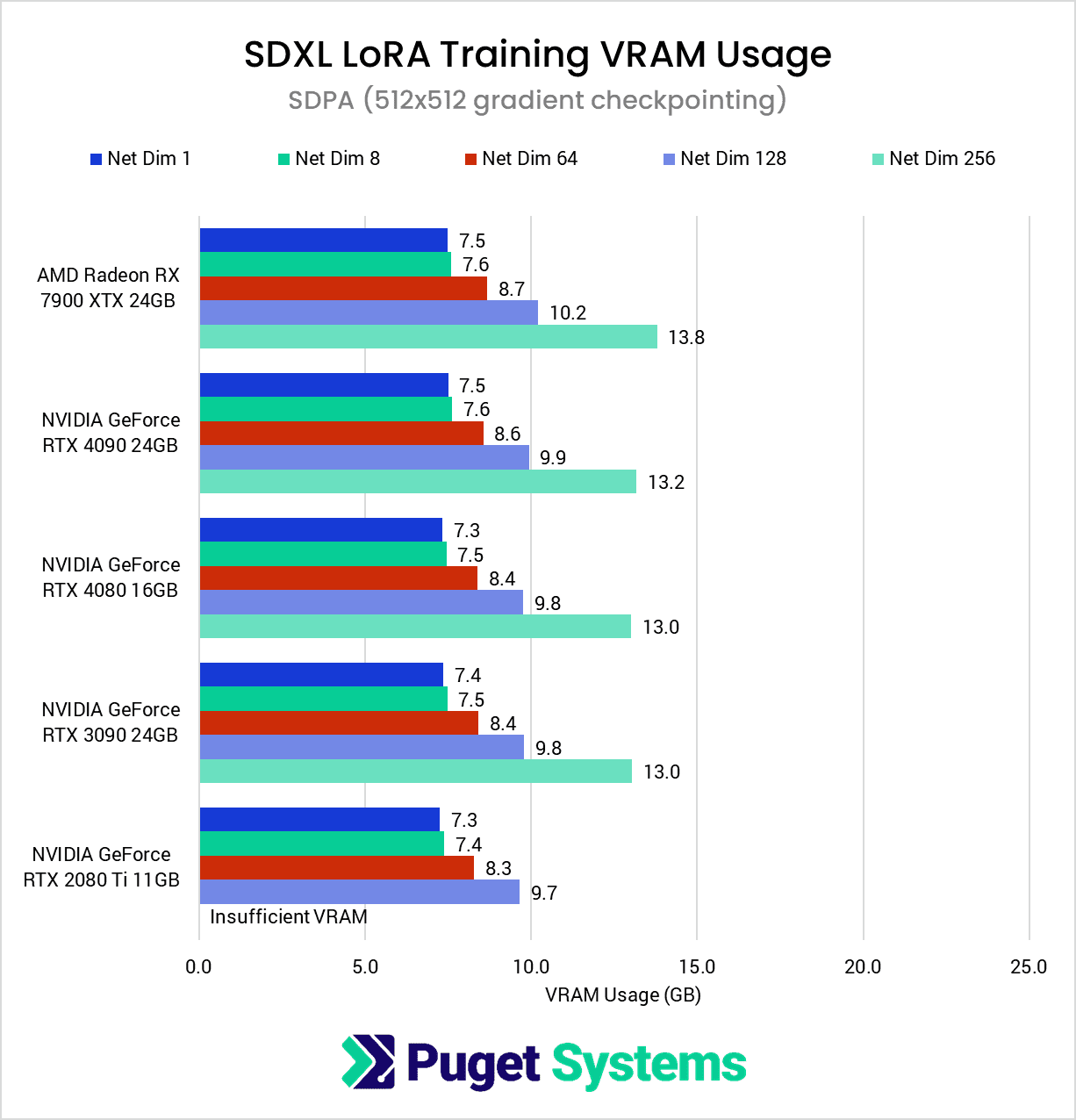
VRAM Usage – 512×512
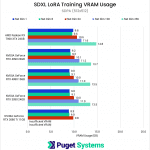
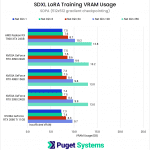
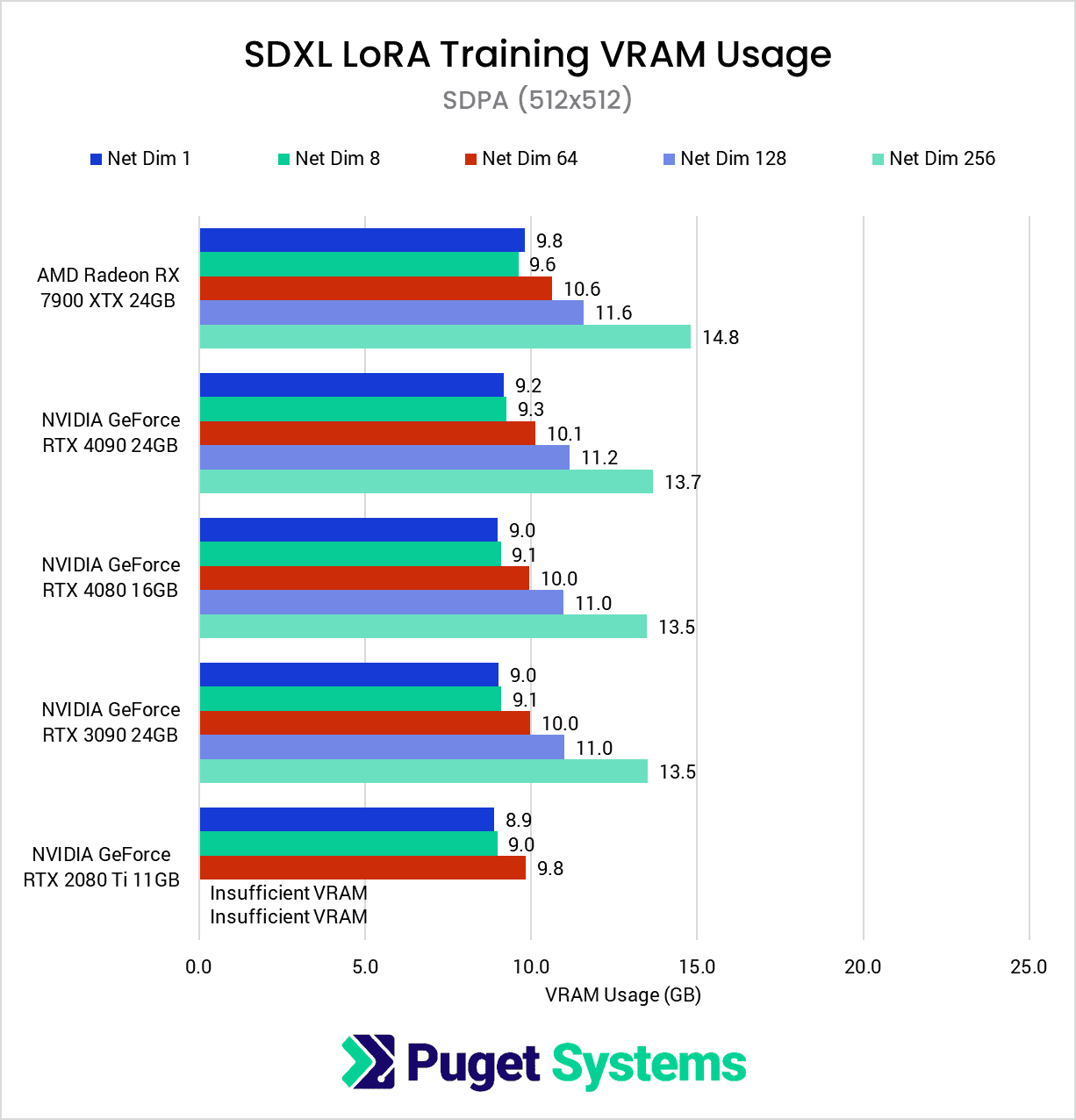
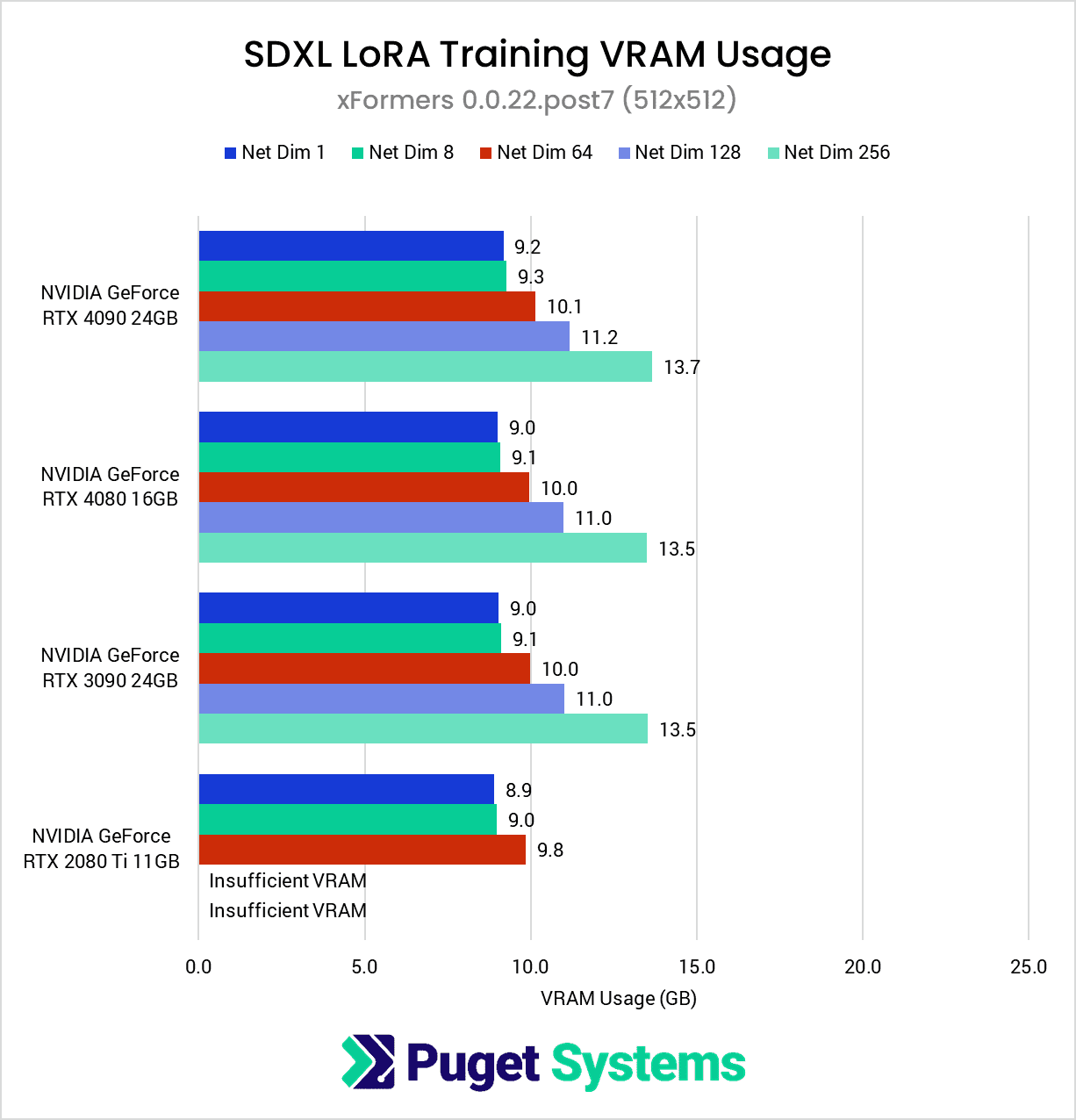
Compared to 1024×1024, the VRAM requirements for the 512×512 dataset are quite modest, generally dropping between ~40-50%. This is enough of a reduction that all of the GPUs except for the RTX 2080 Ti were able to complete the test suite without the use of gradient checkpointing.
Enabling gradient checkpointing for the lower-resolution dataset did not have as dramatic of an effect on VRAM usage compared to the original dataset, only reducing usage by about 15-20% at most. It did allow the RTX 2080 Ti to complete the 128-dimension test, but even with gradient checkpointing at 512×512, the 256-dimension test was still too much for the 11GB card.
Conclusion
These results show that consumer-grade GPUs are capable of training LoRas, especially when working with smaller resolutions like 512×512, which is the default for SD1.5. However, when training using higher-resolution images, such as 1024×1024 for SDXL, we quickly begin to run into VRAM limitations on GPUs with less than 24GB of VRAM.
Despite that, the gradient checkpointing option reduces VRAM usage to the point where even 10-12GB cards can be used for LoRA training with a range of network dimensions and dataset resolutions. However, GPUs featuring 24GB of VRAM will offer the most flexibility for training parameters, and Ada-generation GPUs from NVIDIA continue to outperform the competition for this type of workload.
Other than VRAM concerns, the big issue for consumer GPUs is that they are not designed for long-term, sustained heavy loads like their Professional counterparts. Occasional training of LoRAs is highly unlikely to cause any hardware problems, but if ML training workloads are something you expect to be running for months or years, we highly recommend investing in a professional-grade GPU such as those we tested in our Stable Diffusion LoRA Training – Professional GPU Analysis article.
If you are looking for a workstation for AI and Scientific Computing, you can visit our solutions pages to view our recommended workstations for various software packages, our custom configuration page, or contact one of our technology consultants for help configuring a workstation that meets the specific needs of your unique workflow.
Looking for an AI and Scientific Computing workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.