Table of Contents
Introduction
Stable Diffusion is a deep learning model that is increasingly used in the content creation space for its ability to generate and manipulate images using text prompts. Stable Diffusion is unique among creative workflows in that, while it is being used professionally, it lacks commercially-developed software and is instead implemented in various open-source applications. Additionally, in contrast to other similar text-to-image models, Stable Diffusion is often run locally on your system rather than being accessible with a cloud service.
Stable Diffusion can run on a midrange graphics card with at least 8 GB of VRAM but benefits significantly from powerful, modern cards with lots of VRAM. We have published our own benchmark testing methodology for Stable Diffusion, and in this article, we will be looking at the performance of a large variety of Professional GPUs from AMD and NVIDIA that were released over the last five years. If you are interested in the performance of Consumer GPUs, we have also published an article covering over a dozen of those.
We want to point out that Tom’s Hardware also published their results back in January for an even wider variety of consumer GPUs. However, we could not fully replicate their results, so the numbers we are showing are slightly different. We do not believe that this is due to any issue with testing methodology from each party, but rather that Stable Diffusion is a constantly evolving set of tools. How it works today is very different than how it did even six months ago.

Image
Below are the specifications for the cards tested:
| GPU | MSRP | VRAM | CUDA/Stream Processors | Single-Precision Performance | Power | Launch Date |
|---|---|---|---|---|---|---|
| RTX 6000 Ada Generation | $6,800 | 48 GB | 18,176 | 91.1 TFLOPS | 300 W | Dec. 2022 |
| RTX A6000 | $4,650 | 48 GB | 10,752 | 38.7 TFLOPS | 300 W | Oct. 2020 |
| Radeon PRO W7900 | $4,000 | 48 GB | 6,144 | 61.32 TFLOPS | 295 W | April 2023 |
| RTX A5000 | $2,500 | 24 GB | 8,192 | 27.8 TFLOPS | 230 W | April 2021 |
| Radeon PRO W7800 | $2,500 | 32 GB | 4,480 | 44.78 TFLOPS | 260 W | April 2023 |
| Radeon PRO W6800 | $2,250 | 32 GB | 3,840 | 17.83 TFLOPS | 250 W | June 2021 |
| Radeon PRO VII | $1,900 | 16 GB | 3,840 | 13.06 TFLOPS | 250 W | May 2020 |
| Radeon PRO W9100 | $1,600 | 16 GB | 4,096 | 12.29 TFLOPS | 230 W | July 2017 |
Test Setup
Test Platform
Benchmark Software
| Automatic 1111 Version: 1.5.1, xformers: 0.0.17 Checkpoint: v1-5-pruned-emaonly |
| Automatic 1111 (lshqqytiger AMD fork) Version: 1.3.1 Checkpoint: v1-5-pruned-emaonly |
| SHARK Version: 20230701_796 Checkpoint: stabilityai/stable-diffusion-2-1-base |
| PugetBench for Stable Diffusion 0.3.0 alpha |
To test the performance in Stable Diffusion, we used one of our fastest platforms in the AMD Threadripper PRO 5975WX, although CPU should have minimal impact on results. Following our test methodology, we used three implementations of Stable Diffusion: Automatic 1111, SHARK, and our custom in-development benchmark and the prompts given in our methodology article.
It is important to note that our primary goal is to test the latest public releases of the most popular Stable Diffusion implementations. While many would consider these to be cutting-edge already, there are even newer things that could be implemented, such as updated CUDA and PyTorch versions. However, these are not always stable and are not yet integrated into the public releases of Automatic 1111 and SHARK. We want to focus on what end-users would most likely use for real-world, professional applications today, rather than testing right at the bleeding edge. However, We will note that our “PugetBench” version of Stable Diffusion uses the latest versions of CUDA and PyTorch (among others) at the time of this article.
Looking for a Content Creation Workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with our technical consultants today.
Automatic 1111
Image
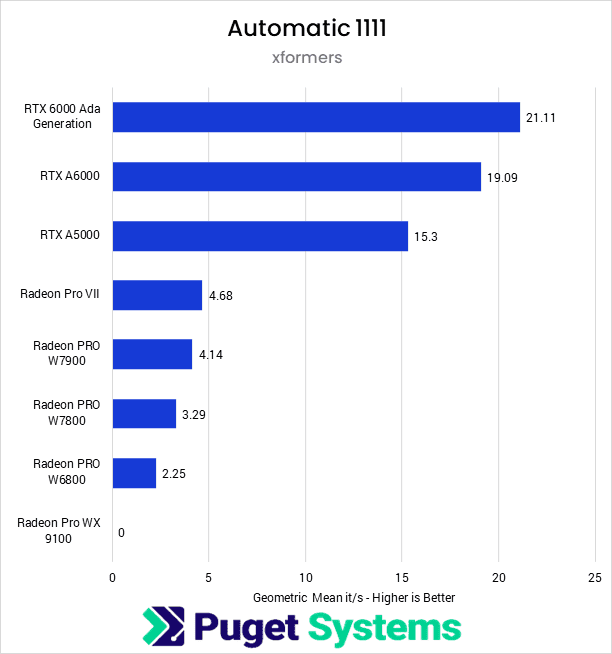
Starting off looking at the Automatic 1111 implementation with xFormers enabled, we see that the NVIDIA cards dramatically outperform the AMD cards, with the slowest NVIDIA card tested–the RTX A5000–having over three times the iterations per second as the fastest AMD card–the Radeon Pro VII. Otherwise, NVIDIA shows expected scaling, with the most expensive RTX 6000 Ada having the highest results, followed by the RTX A6000. Given the price gap between the 6000 Ada and the A6000, it may not be worth the relatively small performance bump.
Automatic 1111 isn’t typically the preferred implementation for AMD GPUs, however, and we see mixed results overall, with the year-old Radeon Pro VII outperforming the three-month-old W7900 by a small amount. The rest of the PRO cards fall in line with expectations, although the Pro WX 9100 did not complete the benchmark with this implementation. It is possible further tweaking could fix the compatibility issue, but we wanted to stick as close to the “stock” setup for each implementation as possible.
SHARK
Image
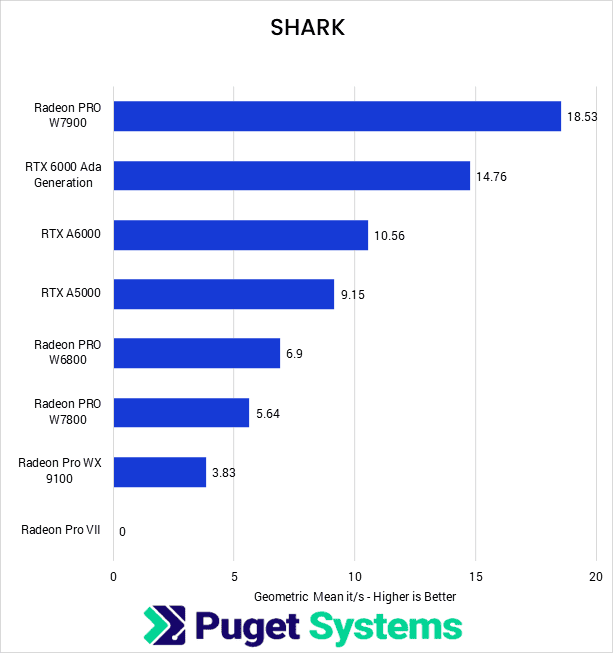
Moving on to SHARK, we see why AMD users tend to favor this implementation. The Radeon PRO W7900 has the highest results of all the cards we tested, followed by the NVIDIA suite in its expected order. Interestingly, the Radeon PRO W6800 had results nearly 20% higher than its new replacement, the W7800–it seems likely this is a bug, but we are unsure if it is with the implementation or our testing. The Radeon Pro VII did not complete testing with the SHARK implementation, likely due to it lacking some newer features that are required by this package.
With AMD topping the board here, it is worth noting that AMD’s W7900 performance with SHARK gives comparable results to NVIDIA’s RTX A6000 in Automatic 1111, making it a viable alternative when using the correct implementation. This shows that using the proper implementation is extremely important as it can have anywhere from a 30% decrease in iterations per second to a massive 400% increase depending on the type of GPU you have.
PugetBench for Stable Diffusion
Image
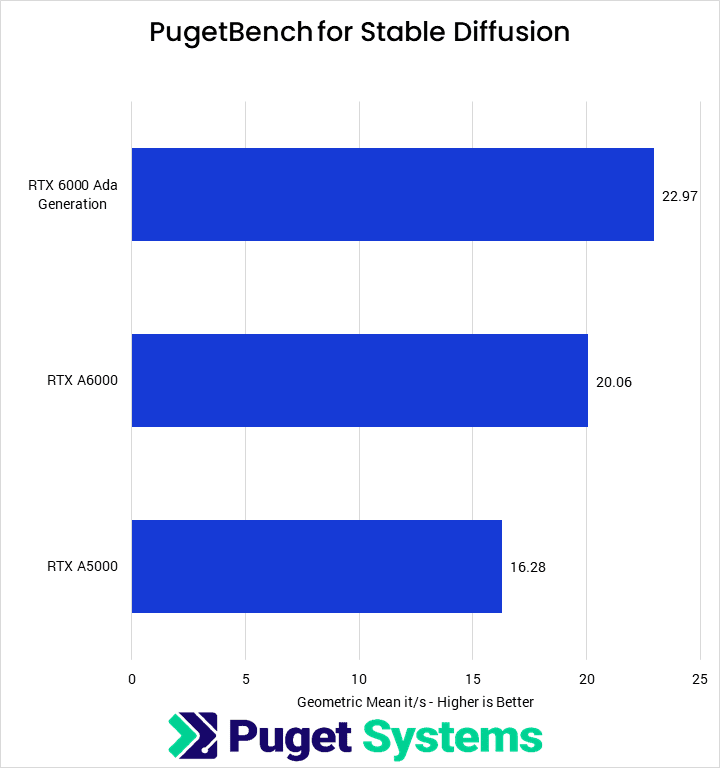
In addition to the two most common packages for Stable Diffusion, we also have our own implementation that is still early in development. We are focusing it on benchmarking, which allows us to remove a lot of the bloat that is necessary when making a robust tool like Automatic 1111 or SHARK. Currently, it only supports NVIDIA cards, although we plan to add AMD support.
This implementation performs almost identically to the Automatic 1111 implementation with xFormers, although it eschews that package in favor of an updated PyTorch library. This means that when Automatic 1111 and SHARK update to the latest version of PyTorch, we likely won’t see a massive performance shift, although it will make the codebase much cleaner.
Looking for a Content Creation Workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with our technical consultants today.
Is NVIDIA RTX or Radeon PRO faster for Stable Diffusion?
Although this is our first look at Stable Diffusion performance, what is most striking is the disparity in performance between various implementations of Stable Diffusion: up to four times the iterations per second for some GPUs. NVIDIA offered the highest performance on Automatic 1111, while AMD had the best results on SHARK, and the highest-end GPU on their respective implementations had relatively similar performance.
Assuming you are not tied to using either Automatic 1111, SHARK, or a different implementation, both AMD and NVIDIA offer similar performance at the top-end, with the AMD Radeon PRO W7900 48GB and NVIDIA RTX A6000 48GB both giving about 19 it/s. This currently gives AMD a slight price/performance advantage, although we will note that developers tend to give priority to NVIDIA GPUs, so that may change in the future. AMD is doing a lot of work in this vertical to improve GPU support, but that hasn’t quite caught up to NVIDIA.
If you have a bit more of a budget, however, NVIDIA is clearly the way to go. The NVIDIA RTX 6000 Ada Generation 48GB is the fastest GPU in this workflow that we tested. Conversely, if you are on more of a “budget”, NVIDIA may have the most compelling offering. The NVIDIA RTX A5000 24GB may have less VRAM than the AMD Radeon PRO W7800 32GB, but it should be around three times faster. If you are training models, the extra VRAM may still make AMD the right route, but if you are generating images, you likely will not need that additional VRAM as most Stable Diffusion models are optimized to generate either 512×512 or 768×7768 images.
Stable Diffusion is still a relatively new technology with rapid ongoing development, so it is worth noting that performance will only improve over the next few months and years. While we don’t expect that there will be a drastic change in relative performance, the results we found in this article are likely to shift over time.
If you are looking for a workstation for any of the applications we tested, you can visit our solutions page to view our recommended workstations for various software packages, our custom configuration page, or contact one of our technology consultants for help configuring a workstation that meets the specific needs of your unique workflow.
Looking for a content creation workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.